

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的 kabutoz1,一名专注于后端开发的工程师。我毕业于湖南科技学院,拥有扎实的计算机科学与技术背景。我的职业生涯起步于中交一公局第六工程有限公司,后期自己通过学习掌握了Python、MySQL、Tableau、HTML5、JavaScript 等多种技术栈,也经历了了一些项目的实践。
在技术实践方面,我曾参与开发 q房网二手房爬虫和豆瓣电影Top250爬虫,这些项目不仅锻炼了我的编程技能,也增强了我对数据抓取和信息抽取的理解。此外,我还负责过一个重要的项目——豆瓣电影Top250爬虫,这个项目让我在数据分析和数据可视化方面有了显著的进步。
我对技术充满热情,熟练掌握 Python、MySQL、Tableau、HTML5、JavaScript 等多种技术栈。在数据分析领域,我运用 pandas、numpy、matplotlib、pyecharts 等工具进行数据处理和可视化展示。同时,我对 CSS 也有深入的了解,能够打造出既实用又美观的前端界面。
如果您有任何技术开发需求,或者希望与我合作,请点击“立即预约”或“发布需求”,我期待与您一起探索技术的可能性。
2022-07-01 -2023-10-15中交一公局第六工程有限公司经营部主管
合同管理:负责项目合同的拟定及项目对下合同的招投标工作; 成本管理:负责项目计量和结算资料及项目施工概预算的编制;对经营文件、台账数据及原始资料的归档整理。 风险管理:跟踪招投标流程,确保招投标流程的合规性;招标流程开始前严格在协作队伍库中选取协作单位,杜绝使用公司协作单位黑名单内的单位。 数据分析:对项目在公司系统上的经营数据(产值、成本、经营活动及经营月报)进行核算分析和整理并定期汇报给公司。
2018-09-01 - 2022-06-15湖南科技学院工程管理本科
主修课程 管理学、应用统计学、经济学、工程经济学、会计学原理、高等数学、概率论与数理统计、线性代数、工程造价案例分析、工程造价、招投标与合同管理等 所获荣誉:获得2019年度优秀学生干部、优秀社团干部 所获证书:英语CET4等

本作品是一个Python脚本,用于实现一个简单的翻译功能,具体是从中文翻译到英文。它利用了百度翻译的API接口,通过模拟HTTP请求来获取翻译结果。以下是该脚本的主要特点: 用户输入:脚本首先通过input函数请求用户输入需要翻译的中文内容。 读取JavaScript代码:脚本读取本地存储的百度翻译所需的JavaScript代码,该代码可能用于生成API请求所需的签名(sign)。 生成签名:使用execjs库执行读取到的JavaScript代码,生成翻译请求所需的签名。 设置请求头部和Cookies:定义了详细的HTTP请求头部(headers)和Cookies,这些信息模拟了一个真实用户的浏览器环境,有助于绕过一些基本的服务器验证。 构造请求参数:设置了请求的参数(params)和数据(data),包括翻译的源语言(from)、目标语言(to)、待翻译的文本(query)、签名(sign)和时间戳(ts)。 发送请求:使用requests库的post方法向百度翻译API发送带有所需参数的POST请求。 处理响应:请求成功后,脚本解析返回的JSON响应,提取并打印出翻译结果。 异常处理:虽然代码中没有明确的错误处理逻辑,但在实际应用中应该添加异常处理来确保程序的稳定性。 用户友好:脚本提供了简单的命令行界面,用户无需了解背后的实现细节即可使用翻译功能。
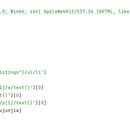
本作品是一个使用Python编写的网络爬虫脚本,旨在从Q房网上抓取深圳地区二手房的相关信息,并将这些信息保存到CSV文件中。程序的主要特点如下: 1.使用lxml库解析HTML:通过lxml.etree模块解析网页的HTML内容,以提取所需的数据。 2.使用requests库发送HTTP请求:利用requests.get方法获取指定URL的网页内容。 3.自定义写入CSV文件的函数:定义了write_to_csv函数,用于将抓取到的数据以追加模式写入到名为xiaoqu_qiufang.csv的CSV文件中。 4.设置请求头:通过自定义HTTP请求头,模拟浏览器访问,以提高请求成功率。 5.循环遍历多页:脚本循环遍历Q房网的多个页面(本例中为前30页),以获取更多的房源信息。 6.XPath定位数据:使用XPath表达式精确定位到页面中包含小区名称、单价和板块信息的HTML元素。 7.异常处理:在写入CSV文件时,通过try...except结构捕获可能发生的异常,以保证程序的健壮性。 8.休眠机制:在每次HTTP请求之间设置2秒的休眠时间,以避免给服务器带来过大压力,并可能减少被网站封禁的风险。 9.进度输出:在抓取每个小区的信息时,脚本会打印出当前正在抓取的小区名称,以便用户了解程序的执行进度。 10.简洁性:整个脚本结构清晰,易于理解和维护,适合作为网络爬虫开发的入门示例。
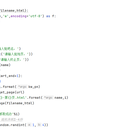
本作品是一个Python编写的网络爬虫程序,专门用于抓取百度贴吧中的帖子。程序通过模拟用户请求,获取指定贴吧的页面内容,并将这些内容保存为HTML文件。该程序具有以下特点: 1.模块化设计:程序将爬虫功能划分为几个模块,包括获取页面、解析页面、写入文件和主运行函数。 2.随机用户代理:为了模拟真实用户的行为,程序使用useragents库随机选择一个用户代理(User-Agent),以绕过一些简单的反爬虫机制。 3.输入参数:用户可以通过命令行输入指定贴吧的名称、起始页和终止页,程序将根据这些参数抓取相应范围内的帖子。 4.动态URL构建:程序使用格式化字符串动态构建请求的URL,其中贴吧名称经过URL编码处理,以确保URL的正确性。 5.异步请求:使用urllib库的request模块发起HTTP请求,并通过设置合适的请求头来获取网页内容。 6.数据保存:程序将获取到的HTML内容保存到本地文件中,文件名包含贴吧名称和页码,方便用户查阅。 7.休眠机制:为了避免对服务器造成过大压力或触发反爬虫机制,程序在抓取每个页面后随机休眠1到4秒。 8.执行时间统计:程序在运行结束时会计算并显示整个抓取过程的执行时间。 9.异常处理:虽然在提供的代码中没有明确的异常处理逻辑,但在实际应用中,应该添加异常处理来确保程序的稳定性。 10.简洁性:程序代码简洁,易于理解和维护,适合作为网络爬虫开发的入门示例。




