

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********本人名为和金权,目前就读于文山学院大三人工智能专业,是一名对计算机科学充满热情的学生。自入学以来,我始终专注于学习人工智能领域的专业知识,并在课程项目中展现出良好的编程能力和团队协作精神。
在学术方面,我积极学习,并在课程项目中展现出良好的编程能力和团队协作精神。此外,我还参加了校级科研项目,负责编写项目的后端代码,积累了实际项目经验。
2024-03-01 -2024-05-29淘宝爬虫兼职
数据采集:根据需求,设计并实施爬虫程序,从指定网站上自动采集所需的数据。 数据解析:利用爬虫程序从原始页面中提取结构化的数据,如文本内容、图片、链接等。 数据存储:将采集和解析后的数据存储到数据库或文件中,以便后续的数据处理和分析。 反反爬机制:针对一些网站可能采取的反爬虫策略,研究和实施相应的方法来应对,确保爬虫的稳定运行。 代码维护:定期更新和维护爬虫程序,确保其能够适应网站结构的变化或其他潜在的技术挑战。 报告编写:根据采集到的数据,编写数据报告,提供给项目团队或客户,帮助他们做出基于数据的决策。 遵守法律法规:在执行爬虫任务时,确保遵守相关的法律法规,尊重网站的版权和隐私政策。
2021-08-26 - 2024-05-29文山学院人工智能本科
在校期间,我始终积极进取,努力提升自己的专业能力和综合素质。通过学术研究、实践活动和社团组织等方面的丰富经历,为我打下了扎实的专业基础和人际交往能力,为未来的发展奠定了坚实基础。
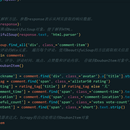
本作品是一个利用Scrapy框架和BeautifulSoup库编写的豆瓣250电影评论爬虫。该爬虫旨在从豆瓣电影网站上获取250部最热门电影的评论数据,并将其存储到本地CSV文件中。 爬虫首先定义了起始URL,并设置了要爬取的页数。通过重写Spider的parse方法,爬虫能够解析网页内容并提取影评信息,包括昵称、评分、评论时间、地点、点赞数和评论内容。这些信息被存储到DoubanItem对象中,并通过生成器表达式返回给Scrapy框架处理。 爬虫使用了Scrapy的follow方法来自动爬取下一页的评论,直到达到设定的页数。整个爬取过程采用了递归的方式进行,以实现对多页评论的连续爬取。
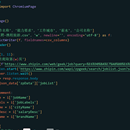
本作品使用Python编程语言和DrissionPage库中的ChromiumPage类,实现了一个针对BOSS直聘网站上携程旅游相关职位信息的爬取工具。该工具能够自动访问指定网址,爬取并解析职位列表的JSON数据,然后将提取的信息存储到CSV文件中。 脚本首先定义了CSV文件的列名,包括工作名称、能力要求、工作城市、薪水和公司名称。随后,脚本通过循环爬取多页职位信息,并对每个职位的信息进行提取,包括工作名称、能力要求、工作城市、薪水和公司名称。这些信息被存储到CSV文件中,以便后续分析和使用。
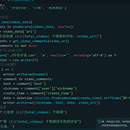
本作品旨在探索抖音平台上的用户评论爬取技术。通过使用Python编程语言和Chromium浏览器驱动,我们实现了一个高效、自动化的小说评论爬取工具。 脚本首先创建了一个ChromiumOptions实例以启用无头模式,然后创建了一个ChromiumPage实例并使用无头模式。通过模拟滚动到页面底部,脚本能够加载更多视频数据。获取视频的URL和ID后,脚本进一步访问每个视频页面,并监听’/v1/web/comment/list/'数据包以获取评论信息。 脚本将获取到的评论数据存储到CSV文件中,包括评论人、评论内容、日期和视频地址。通过这种方式,我们可以了解到用户对特定视频的看法和态度,为我们的分析提供有价值的信息。



