

爬虫
0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2024-04-01 -2024-05-23勿思量网络科技爬虫工程师
进行网络爬虫和数据采集的接单,不同的反扒机制利用不同的技术,对于那些没有任何反扒,可以直接通过httpClient,就不必大动干戈,在分析协议或加密数据前多看看网站牛人的帖子,他们已经帮你分析好的,没必要自己埋头干,最后重要的一个点,就是一定要注意频率,特别对于有些抗流量很弱,但又很重要的网站应用,不然被人家告上去蹲个监狱还真不好说。
2022-09-01 - 2024-05-23兰州资源环境职业技术学院机器人技术本科
在校期间自学python编程语言及excel数据分析等编程性技能
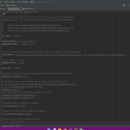
1.使用scrapy框架对网易新闻进行信息及正文爬取 2.注意网易新闻不是一次性加载出来的,需要多次点击“加载更多”,才能获取全部新闻资讯
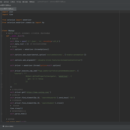
1.使用鼠标链对网页进行加载全部数据的操作 2.使用基本的爬虫语言对数据信息进行抓取并存储为json格式 3.注意苏宁易购的商品是异步加载,需要将滚轮滑倒最底部才能获取到全部的数据
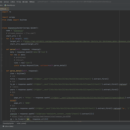
1.作品使用scrapy框架进行异步爬取 2.主要负责网站抓取需要信息,存储为excel格式 3.注意频率,频率太高会被后台检测到导致封号和反爬等一系列触处罚




