

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2020-09-14 -2022-10-31西安华为研究所后台工程师
主导实现了Webswing的负载均衡模式,允许无插件化访问Swing应用程序。 开发了自升级功能,适配WinServer和WinPC环境,针对沃达丰的安全需求提供了升级包的签名部分。 设计并实施了Elasticsearch的SSL插件,增强了数据传输的安全性。
2016-08-31 - 2020-06-30西安电子科技大学软件工程本科

模型配置与加载 应用首先定义了一个配置对象detectorConfig,指定了使用ResNet50作为PoseNet的骨干网络,并设置了输入图像的分辨率和其他相关参数。 姿态检测 接收一个已经加载的模型和一个图像元素作为参数,然后使用模型的estimatePoses方法来估计图像中的姿态。这个方法返回一个包含所有检测到的姿态的数组,每个姿态由关键点的坐标和置信度分数组成。 图像上传处理 handleImageUpload函数用来处理用户通过文件输入上传的图像。当用户选择一个图像文件后,该函数使用FileReader API读取文件内容,并将其设置为图像元素的源,以便在网页上显示。 姿态分析按钮 handleAnalyzeButtonClick函数在用户点击“分析”按钮时触发。它首先加载模型,然后对上传的图像进行姿态检测,并调用displayPoses函数来显示检测结果。 绘制关键点和连线 drawKeypoints和drawLines函数分别负责在Canvas上绘制关键点和它们之间的连线。这些函数接收Canvas的上下文、关键点数组和颜色作为参数,然后根据这些参数在Canvas上绘制姿态。关键点组(通常为17组)代表了人体的主要关节位置。 显示姿态结果 displayPoses函数是显示姿态检测结果的主要函数。它首先清除Canvas上之前的绘制内容,然后将原始图像绘制到叠加Canvas上。接着,它遍历检测到的每一个姿态,使用drawKeypoints和drawLines函数在Canvas上绘制关键点和连线。
1.录音功能: 通过MediaRecorder API接入多媒体设备,如麦克风,结合静默检测功能来识别用户的说话状态。在指定时间内未检测到声音时,使用audioChunks模块记录音频并转换为语音格式,然后上传到后端。在此过程中,之前的录音内容将被清空,以便开始新的录音循环。 2.音频转换: 使用FFmpeg工具去除音频中的静音部分,并将音频转换为16000Hz采样率、16位小端格式编码的单声道音频,以优化音质和文件大小。 3.音频转文字: 利用paddlespeech的语音识别功能,将用户的语音输入准确地转换为文本,以便进行进一步的处理和分析。 4.获取聊天内容: 将转换后的文本通过Kimi API发送,获取智能生成的聊天内容,这些内容将作为聊天机器人的回复。 5.文字转音频: 使用paddlespeech的文本到语音(TTS)功能,将聊天机器人的文本回复转换为清晰的音频内容,供用户听取。 6.消息接收与展示: 在前端界面上展示用户和聊天机器人的交流内容,包括文字和音频消息,提供直观的沟通体验。
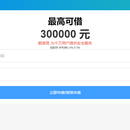
前台(用户界面) 二维码扫描入口:用户通过扫描由后台生成的二维码进入贷款申请页面。 贷款金额展示:在申请流程的开始,向用户展示可贷款的金额范围。 基本信息填写:用户需要填写一些基本信息,如姓名、身份证号、联系方式等。 详细信息填写:用户需提供更详细的财务信息,包括房产、公积金情况等。 生成可贷款金额:根据用户填写的信息,系统自动计算并展示用户可贷款的金额。 填写贷款信息:用户完成贷款申请的最后步骤,包括选择贷款期限、利率等,并提交申请。 后台管理系统 后台管理系统是为贷款机构的管理人员设计的,用于管理贷款申请和用户信息。主要功能模块包括: 二维码管理: 生成贷款策略:生成不同标准的贷款策略,如最大金额,年利率等。 生成二维码:为贷款申请创建独特的二维码。 用户管理: 用户信息审核:审核用户提交的基本信息和详细信息。 用户借贷纪录:纪录用户的借款纪录。 使用了flask框架,vue3+element-plus以及





