

MySQL
服务器运维
自动化运维
K8S
0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********目前担任 SRE 工程师。作为一名站点可靠性工程师,我的主要职责是确保系统的高可用性、可扩展性和性能优化。
我拥有 四年的 IT 行业经验,专注于构建和维护可靠的分布式系统。在过去的工作中,我参与了多个大型项目,从架构设计到系统运维,积累了丰富的经验。以下是我的一些主要技能和经验:
系统监控与告警:熟练使用 Prometheus、Grafana 等监控工具,搭建全面的监控和告警系统,实时监控系统性能和健康状态。自动化运维:精通 Ansible、Puppet、Chef 等配置管理工具,能够通过编写脚本实现自动化部署和管理,提升运维效率。熟悉 CI/CD 工具如 Jenkins、GitLab CI,能够自动化构建、测试和部署流程,保证系统的持续集成和交付。故障排除与应急响应:具备快速定位和解决系统故障的能力,能够在系统出现故障时迅速响应,降低故障对业务的影响。有丰富的故障排查经验,熟悉各种日志分析工具,能够快速找到问题根源并解决。性能优化:熟悉系统性能调优的方法,能够通过分析系统瓶颈进行优化,提高系统响应速度和处理能力。具备数据库优化经验,熟悉 MySQL、PostgreSQL 等数据库的优化方法。高可用架构设计:擅长设计和实现高可用系统架构,使用负载均衡、缓存、分布式存储等技术提高系统的可用性和容错能力。安全管理:具备系统安全加固的经验,熟悉常见安全漏洞及其防护措施,能够保证系统的安全性。我始终坚信,通过自动化和优化,我们可以大大提升系统的可靠性和运维效率。我喜欢挑战和解决复杂的问题,并乐于与团队合作,共同实现高质量的技术解决方案。
谢谢大家,希望能有机会与各位合作,一起推动项目的发展。
APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
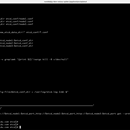
备份现有配置 在进行任何操作之前,备份现有的 Kubernetes 配置和证书文件。确保有完整的备份,以防操作过程中出现问题。 2. 生成新的 CA 证书 使用证书生成工具生成新的 CA 证书和密钥。 3. 更新 Kubernetes 配置 将新的 CA 证书更新到 Kubernetes 配置中,主要包括以下组件: API 服务器:更新 API 服务器的证书和密钥。 etcd:更新 etcd 集群的证书和密钥。 Controller Manager 和 Scheduler:更新 Controller Manager 和 Scheduler 的证书和密钥。 Worker 节点:更新 kubelet 和 kube-proxy 的证书和密钥。 4. 分发新的证书 将新的 CA 证书分发到所有的 Kubernetes 节点,包括 Master 和 Worker 节点。确保每个节点都更新了新的 CA 证书和密钥。 5. 重启 Kubernetes 组件 在所有节点上重启 Kubernetes 组件,以使新的证书生效。这通常包括 kubelet、API 服务器、Controller Manager、Scheduler 和 etcd。 6. 验证集群状态 确保所有组件都正常运行,并验证新的证书是否生效。检查节点和系统命名空间下的 pod 状态。 总结 替换 Kubernetes CA 证书是一个涉及多步骤的过程,需要谨慎操作。通过定期替换证书,可以提升集群的安全性和可靠性。
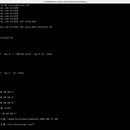
获取主机 IP 地址: 使用 hostname -i 获取当前主机的 IP 地址,用于后续监控数据的获取。 监控 etcd 日志中的错误数量: 通过 grep 命令从 /var/log/messages 日志文件中查找与 etcd 相关的错误信息,并统计错误数量。 检查 etcd 集群的 put 和 get 操作状态: 使用 etcdctl 工具执行 put 和 get 操作,以确认 etcd 集群是否正常工作,并统计操作的执行结果。 获取并解析 etcd 的 Prometheus 指标: 使用 curl 命令从 etcd 的 /metrics 接口获取 Prometheus 格式的监控指标。 解析以下关键指标: etcd_server_leader_changes_seen_total:主从变化次数 etcd_server_has_leader:主节点数 etcd_mvcc_db_total_size_in_bytes:etcd 存储使用空间,转换为 GB process_resident_memory_bytes:etcd 使用的内存,转换为 GB process_open_fds:etcd 的打开文件描述符数(连接数) 将所有获取的监控数据打印输出,包括日志错误数量、put 和 get 操作状态、etcd 存储使用空间、内存使用、主从变化次数、主节点数和连接数。 根据 curl 命令的执行结果,输出 etcd 的运行状态(正常为 0,异常为 1)。
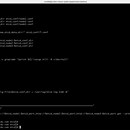
自动化备份恢复 备份的必要性: 防止数据丢失:硬件故障、人为错误或恶意攻击都可能导致数据丢失。 提供恢复点:可以在出现问题时快速恢复到最近的健康状态。 符合合规要求:某些行业法规要求定期备份数据。 备份策略: 定期备份:设定自动备份任务,按计划定期进行备份(如每天、每周)。 增量备份:仅备份自上次备份以来发生更改的数据,以节省存储空间和备份时间。 全量备份:备份整个 etcd 数据库,通常在较长的时间间隔(如每月)进行。 远程存储:将备份文件上传到远程存储,如 AWS S3、Google Cloud Storage 或其他对象存储,以防止本地数据丢失。 自动化恢复 恢复的必要性: 快速恢复:在发生故障时,能够快速恢复服务,减少停机时间。 测试和开发:恢复到特定状态以进行测试或开发。 恢复策略: 从最新备份恢复:通常从最新的全量备份或增量备份恢复,以最大程度减少数据丢失。 基于时间点恢复:根据特定时间点恢复,以恢复到特定的历史状态。




