

0
1
2
3
4
5

APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
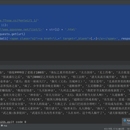
使用 Python 中的正则表达式时,通常用于匹配、查找或替换特定模式的文本。下面我将为你提供一个简单的方案,演示如何使用 Python 的 re 模块来执行基本的正则操作。这个示例将包括模式匹配和文本查找功能。
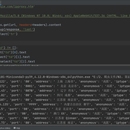
Beautiful Soup (bs4) 是一个用于解析HTML和XML文档的Python库,它并不直接涉及加密或解密的功能。如果你想要使用Python进行加解密操作,可能需要其他库,比如 cryptography 或者 pycryptodome。这些库可以帮助你实现各种加密算法,如AES、RSA等。
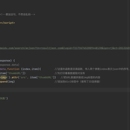
爬虫工程师采集 1688,京东,亚马逊等电商平台的数据 1.根据关键字搜索到所需要的数据 3.破解各种反爬措施(ip风控,请求参数逆向破解,验证码破解) 2.分布式规模采集数据(能日抓30万张页面,重构为异步爬虫,并优化网络性能与重新设计抓取策略,让单台低配置机器定向抓取200万张页面,后负责维护该爬虫) 4.将数据清洗入库使用 MongoDB、MySQL 存储





