

0
1
2
3
4
5

2023-07-01 -至今无无
目前大一在读 1.持有国家信息安全水平考试(NISP)一级证书,具备扎实的网络与系统安全知识基础。 2.积极参与大学生电子创新大赛,展现出卓越的技术创新与实践能力。 3.熟练掌握脚本开发技能,能独立完成多项技术任务,有效提升工作效率与质量。
2023-09-01 - 武昌职业学院计算机网络技术专科
1.持有国家信息安全水平考试(NISP)一级证书,具备扎实的网络与系统安全知识基础。 2.积极参与大学生电子创新大赛,展现出卓越的技术创新与实践能力。 3.熟练掌握脚本开发技能,能独立完成多项技术任务,有效提升工作效率与质量。 4.多次获得校内表彰,体现出优异的学术表现与团队协作
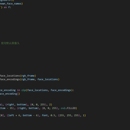
一个基于计算机视觉的人脸识别系统,主要利用了`face_recognition`库来处理图像中的面部特征,并使用`cv2`(OpenCV)来进行实时视频流处理与显示。以下是针对此系统在产品描述方面的几个关键点: 前端采集与显示: -视频流采集:通过调用`cv2.VideoCapture(0)`来获取设备默认摄像头的实时视频流。 -实时显示:使用`cv2.imshow()`函数显示处理后的视频流,其中包含识别到的人脸及其标签。 后端处理与分析: -图像处理:`face_recognition`库用于检测图像中的人脸位置以及提取面部特征编码。 -机器学习模型:采用K近邻分类器(KNN),通过`sklearn.neighbors.KNeighborsClassifier`进行训练,以识别不同个体的面部特征。 -模型存储与加载:使用`pickle`模块序列化和反序列化模型,以便于持久化存储和再次加载使用。 业务模型 数据准备: -已知人脸数据集:从指定文件夹读取存储的面部图片,这些图片被组织成不同的文件夹,每个文件夹代表一个特定的人。 -数据加载:通过`load_known_faces`函数加载所有已知人脸的图片和对应的标签。 模型训练与应用: -模型训练:使用收集到的面部特征编码和对应的名字标签对KNN分类器进行训练。 -模型应用:在实时视频流中,对捕获的每一帧图像进行面部特征提取,然后利用训练好的模型预测面部所属的个体。 功能结构 1.数据加载:读取本地存储的人脸图像和标签。 2.模型训练:基于收集的面部特征编码训练KNN分类器。 3.模型持久化:将训练好的模型保存至本地文件。 4.模型加载:从本地文件加载已经训练好的模型。 5.实时人脸识别:在摄像头捕捉的视频流中实时检测并识别面部,同时在视频上标注识别结果。 6.用户交互:提供退出机制,用户可以通过键盘输入‘q’键来停止视频流处理。 整个系统设计简洁高效,可以快速部署于各种需要实时人脸识别的应用场景中,如安全监控、门禁系统、个人身份验证等。通过预先收集的面部数据集进行模型训练,可以达到较高的识别准确率,同时利用实时视频流处理技术,确保了系统的实时性和交互性。
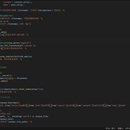
项目分为五个部分 多个爬取脚本,批量执行,清理,可视化,整理 其中重点为整理部分的脚本 主要功能如下: 1.编码检测:脚本使用`chardet`库自动检测每个文本文件的字符编码,确保在读取文件内容时的兼容性。 2.新闻解析:它读取每个`.txt`文件,通过正则表达式提取新闻条目,识别标题、链接、来源、内容和发布日期等关键信息。 3.HTML清理:对于新闻内容中的HTML标签,脚本使用`BeautifulSoup`库进行清理,确保文本干净无杂。 4.数据整理:将提取的信息存储为字典格式,并进一步转化为PandasDataFrame,便于数据分析和操作。 5.TF-IDF向量化:利用`scikit-learn`库中的`TfidfVectorizer`对新闻内容进行向量化,用于后续的相似度计算。 6.余弦相似度计算:基于TF-IDF向量,使用`cosine_similarity`函数计算新闻之间的相似度,以识别潜在的重复新闻。 7.重复项识别与删除:设定一个相似度阈值(如0.5),将相似度过高的新闻标记为重复项,并从DataFrame中移除。 8.结果输出:最后,脚本将去重后的新闻数据保存到一个新的文本文件`每日快讯.txt`中,确保输出的新闻是经过筛选和清理的。
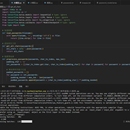
一个深度学习模型,能够理解和生成类似真实世界的密码,这有助于增强密码策略的安全性和复杂性评估 技术栈: -Python:主要的编程语言。 -NumPy:用于数值计算。 -TensorFlow:开源机器学习框架,用于构建神经网络。 -Keras:高级神经网络API,运行在TensorFlow之上,用于简化模型的定义和训练。 -tqdm:进度条库,用于显示训练过程中的进度。 功能: 1.数据加载:从文本文件`passwords.txt`读取密码列表。 2.数据预处理: -字符集提取:识别所有唯一的字符。 -密码编码:将每个字符转换为其索引表示。 -序列创建:将密码转换为固定长度的序列。 3.模型构建: -双层LSTM模型,用于学习密码的结构和模式。 -输出层使用softmax激活函数,预测下一个字符的概率分布。 4.训练流程: -使用数据生成器动态地产生训练批次。 -模型使用`categorical_crossentropy`损失函数和`Adam`优化器进行训练。 -训练过程中保存最佳模型权重。 5.监控与评估: -进度条显示每轮训练的进度。 -训练历史记录可用于后续分析模型性能。 应用场景: -安全研究:生成密码以测试系统安全性。 -教育工具:展示密码强度的重要性。 -密码策略评估:帮助设计更有效的密码策略。 未来改进: -增强安全性:引入更复杂的密码学特征。 -多语言支持:处理不同语言的字符集。 -用户界面:创建交互式界面,让用户可以生成和分析密码。 此项目是一个强大的密码分析工具,可以作为密码安全领域的研究基础,或用于教育目的,提高人们对密码安全重要性的认识。




