

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2024-06-01 -2024-12-01贵州原点科技有限公司ai训练师
明白啦,下面这段工作经历的描述突出了你的相关技能和工作内容,你可以参考看看: [公司名称] - 数据标注员([入职时间]-[离职时间]) 担任 AI 训练师,负责数据标注工作,同时运用 Python 技能为公司开发功能性脚本。通过编写脚本高效抓取标注所需的数据,并进行细致的数据清洗与统计,保障标注数据的准确性和可用性。凭借脚本实现自动化接单流程,有效提升了工作效率,为团队项目推进提供了有力支持
2021-09-01 - 贵州大学明德学院计算机科学与技术本科
系统学习计算机科学与技术专业课程,掌握扎实的计算机基础知识与编程技能。学习内容涵盖数据结构、算法设计、操作系统等核心课程,具备了良好的专业理论
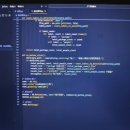
这段Python脚本是一个用于统计快递选框项目中特定标签数量的工具,适用于从大量JSON标注文件中统计甲方结算所需的框数量,具体功能如下: 1. 导入模块 导入了 os 模块用于操作系统交互, json 模块用于解析JSON文件, defaultdict 用于处理默认值字典,以及 tkinter 及其相关子模块用于创建图形用户界面(GUI)。 2. 定义统计单个JSON文件中标签数量的函数 count_labels_in_json 函数接收一个JSON文件路径作为参数。它尝试打开并读取该JSON文件,检查文件中是否存在 shapes 字段。如果存在,遍历其中的每个形状(shape),提取其 label 属性,并使用 defaultdict 统计每个标签出现的次数。若文件解析失败或处理过程中出错,会打印相应的错误信息。 3. 定义统计目录中所有JSON文件标签数量的函数 count_labels_in_directory 函数接收一个目录路径作为参数。它会遍历该目录及其子目录下的所有文件,筛选出扩展名为 .json 的文件。对于每个JSON文件,调用 count_labels_in_json 函数统计其中的标签数量。然后,分别统计标签为 package 和 people 的出现次数,并返回这两个标签的总计数。 4. 定义按钮点击事件处理函数 on_button_click 函数通过弹出对话框让用户输入要统计的目录路径。如果用户输入了路径,就调用 count_labels_in_directory 函数统计该目录下的 package 和 people 标签数量,并将统计结果拼接成字符串。最后,通过消息框显示统计结果。 5. 创建GUI界面 使用 tkinter 创建一个简单的图形用户界面窗口,设置窗口标题为“350M标签
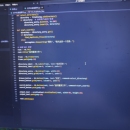
这段Python脚本的主要功能是在指定目录中查找重复文件名的文件,适用于你数据标注后检查是否存在标重数据的场景,具体实现过程如下: 1. 导入模块 导入了用于操作系统交互的 os 模块、处理字典的 defaultdict 、构建图形用户界面(GUI)的 tkinter 相关模块,用于后续的各项操作。 2. 定义查找重复文件函数 find_duplicate_files 函数接收一个目录路径作为参数。它会遍历该目录及其子目录下的所有文件,将文件名作为键,文件路径列表作为值,存储在一个字典 file_dict 中。之后,检查字典中每个文件名对应的路径列表长度,如果大于1,就表示该文件名存在重复,将相关信息输出,并统计重复文件的总副本数。 3. 定义选择目录函数 select_directory 函数使用 filedialog.askdirectory() 弹出对话框让用户选择一个目标目录。如果用户选择了目录,就将该目录路径插入到界面的输入框中。 4. 定义开始搜索函数 start_search 函数获取用户在界面输入框中填写的目录路径,调用 find_duplicate_files 函数开始查找该目录下的重复文件名文件。如果用户没有选择目录,则弹出警告提示框。 5. 创建GUI界面 使用 tkinter 创建了一个简单的图形用户界面,包含选择目标目录的标签和输入框、“浏览”按钮用于选择目录、“查找重复文件”按钮用于启动查找功能,以及一个用于显示查找结果的文本框。 运行该脚本后,用户可以通过界面选择目标目录,点击“查找重复文件”按钮,脚本就会自动检查该目录下是否存在文件名重复的情况,并将结果显示在界面的文本框中,方便你快速定位可能标重的数据 。

这段Python代码主要实现从指定网站批量抓取新闻数据,并对数据进行处理和可视化的功能,具体步骤如下: 1. 导入模块 导入了多进程处理、操作系统交互、HTTP请求、JSON处理、数据可视化和计数器等多个模块,用于后续的各项操作。 2. 创建目录 检查当前目录下是否存在名为 xx 的文件夹,如果不存在,则创建该文件夹,用于存储后续抓取的JSON数据文件。 3. 设置请求头和基础URL 设置了模拟浏览器的User-Agent请求头,防止被网站识别为爬虫;定义了基础URL,用于构建请求的具体URL。 4. 定义抓取函数 run 函数接收页码作为参数,构建完整的请求URL,向网站发送GET请求。若请求成功(状态码为200),则将返回的数据保存为JSON文件;若请求失败,打印错误信息。 5. 多进程抓取 在主程序入口( if __name__ == '__main__': )中,使用多进程池( Pool )并发地调用 run 函数,抓取前50页的数据。 6. 数据提取 遍历存储JSON文件的文件夹,读取每个JSON文件,提取其中的新闻标题和作者信息,将其存储到 results 列表中。 7. 保存提取结果 将提取的标题和作者信息保存到一个文本文件中。 8. 数据可视化 统计每个作者的文章数量,使用 seaborn 和 matplotlib 库绘制柱状图,展示每位作者的文章数量,并保存为图片,同时显示图片 。





