

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********12年java开发经验,擅长高并发、分布式、高可用的服务器端架构,熟悉SpringCloud微服务架构,熟悉大数据常用组件:Hadoop,Hive,HBase,Spark,Zeppelin参与过大数据实验平台框架搭建和开发,参与过Zeppelin源码修改,并贡献给GitHub社区,本人成熟稳重,对工作认真负责!
2017-12-01 -至今江西云澳科技有限公司大数据技术总监
负责大数据实验管理系统需求架构设计,主要是对大数据教学工作进行统一规划、统一数据管理,统一实验平台, 实现教学、科研、管理和服务的各种资源应用高效性。实现学校与企业的紧密合作,帮助学校建立高质量的大数据教育专业,分别有大数据后台管理系统、大数据框架平台、大数据实验分析平台
2010-05-01 -2015-05-01泰豪软件股份有限公司研发经理
流程引擎重构:基于osworkflow开源框架重构,层次清晰,扩展性强 表单重构:精简模型 成就: 1.性能:熟悉JVM参数调优,memcached缓存配置,Y掌握JMeter,LoadRunner压力测试工具基本使用 2.Linux:熟悉基本命令使用,shell脚本编程
2002-09-01 - 2006-06-01华中科技大学计算机科学与技术本科
学习java,c,数据结构等课程,并在学习期间参加了java相关培训
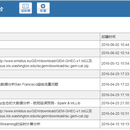
大数据分析平台支持交互式地数据分析,方便做出可数据驱动的、可交互且可协作的精美文档,可以接入不同的数据处理引擎,包括 Flink、Spark、Hive、Scala、SQL、SparkSQL、shell, markdown、MySql等,可实现你所需要的数据采集,数据发现,数据分析,数据可视化和协作,主要功能有: “适配器配置和绑定”配置需绑定适配器的连接信息,如Hive、Hbase、Spark等; “数据分析”通过”%组件名”引用组件进行数据分析,支持多视图展示:图表、柱状图、饼状图等; “权限控制”主要有Owners、Readers、Writers三种权限,admin拥有最大权限。
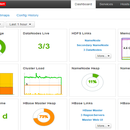
大数据框架平台主要用于创建、管理、监视 Hadoop 的集群(例如 Hive、Hbase、Spark、Sqoop、Zookeeper 等),具体功能如下: 采用图形化方式安装大数据组件,可以方便在指定 的master所在的节点,使集群快速运行起来; 实现集群状态监控,并通过Grafana进行数据的展示(CPU、内存、负载等); 集群部署后,可以方便的通过dashboard进行参数修改,如HDFS的core-site等; 节点快速扩展,快速增加大数据组件,如Hbase、Kylin等; 可定制的Alert功能,报警信息可以自定义,用户可以根据自己的需要,设置哪些情况下需要报警,哪些不需要。
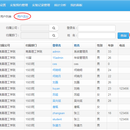
后台目前设置了7个功能模块: “系统管理”是系统的基础模块,可以在这里对用户角色和权限进行设置等; “实验信息”录入实验基本信息,包括实验名称、实验内容、实验要求、实验目的,并设置实验安排表,以便学生预约实验; “学生预约”根据实验安排表预约需要参加的实验; “老师审批”老师针对学生提交的实验预约申请进行审批:通过、拒绝; “学生记录实验”实验完成后记录实验完成情况,出现的问题以及解决方案; “老师评分管理”根据学生所做实验的完成情况进行评分,并给予评语。 “统计分析管理”从三个维度:学校总体情况分析、实验信息分析、实验分数分析对实验进行全方面的分析。







