


0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********1. 熟练掌握requests、scrapy、selenium等相关爬虫模块
2. 熟练掌握mysql、redis等常用的数据库
3. 熟练掌握django,能够独立开发web项目
4. 熟练掌握git
5. 能够独立设计模块级应用的技术方案并完成开发工作
6. 掌握http协议,熟悉html、dom、xpath等常见的数据抽取技术
7. 具有良好的敬业精神、团队协作精神,能承受一定的工作压力,具有良好的沟通能力、较强的文字表达能力
8. 有很强的学习能力、分析能力和解决问题的能力。
2017-06-20 -至今清华大学土木系研究所后端工程师
1.app后台开发 2.api接口开发 3. 负责百度百科、搜狗百科、如腾讯、网易等新闻网站爬虫开发,数据清洗
2008-09-01 - 2012-07-01陕西科技大学艺术设计本科
无
1. 输入指定的阿里巴巴店铺网址爬取该店铺的所有分类和各分类下商品信息 2. 将阿里巴巴商品所涉及到图片信息自动上传到指定的wordpress网站上。 3. 将阿里巴巴商品信息导出指定格式的文件,上传到wordpresss网站商品中。 使用模块: django requests
核心功能 1. 关键词的批量导入和结果批量导出 2. wordpress网站的批量导入和单个导入 2. 关键词从自动分配所属的wordpress网站,生成的文章,自动翻译、添加超链接、自动发布到wordpress网站上。 使用模块: django request 工作难点: 1. 基于wordpress的api,使用python写了一套wordpress对应的爬虫脚本
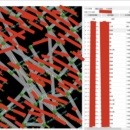
项目分为: 1. 从信号机提取算法需要相关的底层数据 2. 基于检测器数据进行数据加工指标 3. 基于流量交叉口单点算法自动分配各个方向的红绿灯时间 4. 基于多个交叉口的干线绿波算法 我负责的模块 1. 数据库设计 2. 客户顿开发及相关接口开发 3. 底层数据提取 4. 单点算法/干线绿波算法开发






