0
1
2
3
4
5

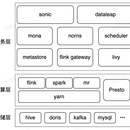
华科本硕,主要从事大数据方向研究和开发工作。对实时流处理比较熟悉,了解常见图处理系统基本原理。在开发方面,主要掌握下面的技能:
熟悉Java,Scala,Python等编程语言,熟悉springboot,mybatis等Java常用框架熟悉并发编程,对Java常见锁和集合都有较深入的了解熟悉hadoop、spark、storm、flink、kafka等常用大数据处理系统。2021-10-15 -至今字节跳动后端研发工程师
正式,从事公司直播业务方向的数据建设。主要负责: 1. 直播相关指标平台的建设 2. 直播相关数据源管理和接入 2. 面向运营策略的数据开发和处理
2020-11-05 -2021-09-28猿辅导大数据开发工程师
实习+正式,负责公司实时数仓建设工作,主要负责: 1. 面向公司所有业务线的流批计算平台的开发和维护 2. flink任务提交服务flink gateway的开发和维护 3. 离线调度系统的设计,开发和维护
2016-07-01 -2017-04-01中兴飞流信息科技有限公司大数据应用开发工程师
实习,从事大数据应用开发工作,主要是实时计算方向。主要完成的项目有: 1. 大数据流处理系统对比评测平台维护 2. 基于apache storm和ffmpeg的营业厅人流实时监测 3. 基于apache storm和车辆识别算法的隧道车流监测
2017-09-01 - 2021-06-01华中科技大学计算机软件与理论硕士研究生
从事大数据实时数据流方面研究,主要方向是实时事件流中的复杂事件识别,该工作被发表在icpp2021
2013-09-01 - 2017-06-01华中科技大学计算机科学与技术本科
华科启明学院卓越工程师班,综合排名前三
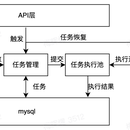
离线调度服务是基于apache dolphinScheduler(ds)来做的。Scheduler服务是最初版本的调度服务,其本质上是一个任务提交服务,即: - scheduler服务存储了用户定义的定时任务元数据,这些元数据描述了任务的定时方式,以及任务启动的参数。 - scheduler服务没有定时能力,它向ds注册定时任务,让ds定时通过http接口向scheduler触发任务运行。 - scheduler服务统一各种类型的任务提交接口,用相同的方式支持包括jdbc类任务、flink batch、spark任务,并管理每个任务实例的全生命周期。 - scheduler本身不存储状态,因此可以很容易地横向扩展。同时支持任务恢复,可以在服务实例挂掉之后对正在运行的实例状态进行恢复。
在大规模时序数据流中实时识别完整事件趋势(CET)在金融服务、实时商业分析和供应链管理等应用中具有重要作用。在完整事件趋势识别过程中可能产生大量中间结果,这些中间结果为CET识别系统带来巨大空间开销,使得CET识别在实际应用中非常具有挑战性。目前国际上最新的方法设计了一种压缩图模型。在这种压缩图中,CET被表示为压缩图中一条路径。这种压缩图模型将不同CET的相同子序列通过图中共同路径进行共享存储。此方法消除了中间结果冗余存储,使得内存空间利用更加高效。然而,每当一个事件到来后,该方法必须遍历压缩图来将这个事件插入到图中。因此,该方法需要?(?2)的时间复杂度来完成?个事件的构图,致使该方法构图时延非常高,难以满足实际应用需求。为了解决这个问题,提出了一种新的基于属性的索引图(ABI Graph)模型。ABI图将事件和事件的属性值具现为图中的两类节点,并使用这两类节点之间的边来表示事件和属性值之间的关联关系,从而将关联事件匹配转化成事件和属性值的匹配。为了从高速事件流中构造ABI图,根据比较器的不同,将匹配模式中谓词进行分类。并根据谓词和每个到来事件的属性来动态生成属性节点,尽量降低属性节点规模以降低构图复杂度。根据ABI图中边的连续性特点,设计了一种范围边表达方式,通过两个范围指针来表达每个事件节点的所有出边,成功将每个事件的构图时间开销和空间开销降低到了?(???(?))和?(1),其中?是ABI图中属性节点个数。同时,基于ABI图中事件构图独立的特点,在动态构图基础上解决属性节点同步问题,设计了一种并行方法来进一步加速构图过程。构图完成后,针对基于BFS的遍历算法高内存开销低时间开销和基于DFS的遍历算法高时间开销低内存开销特点,设计了一种基于锚节点的并行遍历算法,结合两种基本算法的优势,高效从ABI图中提取所有CET。同时,基于流行分布式计算引擎设计了一种分布式CET提取算法,克服了单机系统物理资源限制问题。最后,通过详细的实验,比较了本方法和最新方法的性能。实验表明,本方法在时间开销上相比最新方法能够达到3个数量级的提升。