

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的杨顺Y,一名爬虫工程师; 负责过瑞数5破解,scrapy爬取网站数据,破解京东h5s加密算法 熟练使用 python,爬虫,js逆向,算法加解密; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2022-03-01 -2023-11-30南京赛融信息技术有限公司数据开发工程师
公司的主要业务是帮银行做交易风险预警,通过客户的交易流水来判断对方是否存在风险交易,我主要做数据处理、数据模型开发和数据采集
2020-04-02 - 2022-06-30湖南生物机电职业技术学院机电一体化专科
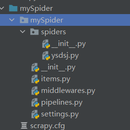
Scrapy是一个基于Python的开源网络爬虫框架,用于快速、高效地抓取网站信息和提取结构化数据。它提供了强大的工具和库,可以帮助用户轻松地创建和管理爬虫程序,从而实现网站数据的抓取、处理和存储。 在Scrapy项目中,包括以下组件: Spiders(爬虫):定义了如何抓取特定网站的规则,包括起始URL、如何跟进链接、如何抓取页面内容等。 Items(数据项):定义了需要抓取的数据结构,类似于模型,用于存储爬取到的数据。 Pipelines(管道):负责处理爬取到的数据,如数据清洗、验证、存储等。 Middleware(中间件):可以自定义扩展Scrapy的功能,例如添加代理、设置用户代理等。 Settings(设置):用于配置爬虫的行为,如并发数、下载延迟、User-Agent等。
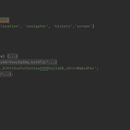
通过hook来找到cookie值生成的地方,用补环境的方式来破解cookie的参数值,用Python对对应网站发送第一次requests请求来获取请求cookie,将请求到的cookie传个逆向后的js,用来生成响应cookie,然后将生成的响应cookie带入到cookie值中对对应网站发送第二次请求来获取数据

通过js逆向的方式对h5st3.1加密算法进行破解,h5st3.1由8个部份组成,其中包括当前时间、fp 浏览器指纹、function的id、token、appid+body+fp+token+rd+function等进行一次加密的返回数据、加密算法的版本、13位时间戳、浏览器ua+pin+fp 的加密,其中主要需要逆向第5部分,先对appid+fp+token+rd+function进行字符串拼接并对其做SHA512加密,在对body进行加密,然后将两个加密结果进行字符串拼接并对其做HmacSHA256加密,第8部分虽然也做了加密处理,但都是系统参数可以直接对其写死





