


0
1
2
3
4
5
 ********
******** ********
********我还是比较细心,编码规范,不泄露客户信息,对源码不开源、不二次售卖。没有多余代码,明确客户需求。涉及领域有:电商、应用程序开发、二次开发、爬虫。曾经参加过后台系统搭建、电脑应用辅助器、渗透人员工具包等,有一定经验。个人博客:https://blog.csdn.net/weixin_45773270
2022-01-02 -2022-08-03 开发者
主要学习过python、MySQL、Linux、django、html、css、jq、js、redis
2022-01-02 - 2022-08-03安阳学院计算机专科
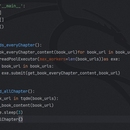
1.大致分为,获取小说链接--->获取小说章节--->获取每一章节小说内容--->将小说进行储存(可以存储在一个文件里|也可以每一章节都是一个文件)。 2.使用了Python中requests、parsel、concurrent、fake_useragent、tqdm和自带的time模块来实现的。
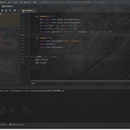
1.产品运用了tkinter模块、re正则、webbrowser包、urllib模块下面的parse包 2.此产品是我与老师共同完成的,老师负责产品规划,代码由我实现 3.难题就是tkinter模块的时候请教了老师2次,现在已经基本掌握.
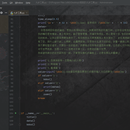
1.该程序主要使用的是while循环及if操作,从而实现登陆界面 2.我独立开发此项目 3.while用来实现用户输入有误的时候让用户重新输入,当输入值为0的时候可以让代码休眠几秒过后重新赋值让输入次数为3,





