

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********➢ 3年J2EE工作经验,6年大数据工作经验
➢ 熟练掌握hadoop底层架构,熟悉原理和部署集群,包括参数优化;
➢ 研究过hadoop、hive、hbase源代码
➢ 熟练使用、维护、优化大数据生态系统常用组件,包HDFS,MR,Yarn,hive,hbase,sqoop、impala、zookeeper、spark、hue、sentry、ElasticSearch、Neo4j、titan等等
➢ 熟练使用、维护实时系统体系。包括:canal、Filebeat、kafka、storm、sparkSteam、kudu等等
➢ 熟悉搭建、使用常用的展示工具,如kylin、apache zeppelin、superset、表报工具、BI工具
➢ 熟悉大数据数据集市,数据仓库建设
➢ 熟悉主流关系型数据库:如Oracle、SQL Server、mysql等
➢ 熟练使java框架开发,spring、springboot、mybatis
➢ 熟练使用python、shell完成脚本开发
2018-01-02 -至今厚相科技高级架构师
➢离线平台架构规划和技术选型,包括ETL工具、调度系统、数仓建设 ➢实时平台整体架构规划和技术选型 ➢监控体系设计和开发实现,包括硬件资源监控,yarn资源监控,数据质量监控,服务状况监控 ➢数据展现系统选型、搭建维护和推广使用 ➢Zeus调度系统二次开发
2016-01-01 -2018-01-01拍拍贷大数据专家
➢离线任务体系的建设 ➢老业务Hive sql优化 ➢反欺诈业务开发(找出黄牛) ➢财务返点系统开发 ➢图数据开发 ➢催收业务迁移大数据平台
2013-03-01 -2015-12-31壹药网大数据架构
➢大数据平台维护 ➢大数据技术引入 ➢实时平台搭建维护 ➢指标系统开发 ➢离线推荐系统开发 ➢表报系统开发
2006-09-01 - 2010-06-30华东交通大学计算机软件与理论本科
软件工程
➢数据仓库命名规范设计 ➢数据仓库分层 ➢维度表,事实表的设计 ➢数据集市的实现 ➢元数据的维护 ➢数据安全设计与实现 ➢数据血缘关系和生命周期
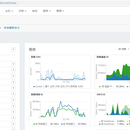
➢离线平台 1)Zeus调度系统; 2) ETL工具,针对调度系统开发的 3) hue对外提供hive、impala查询; 4) 离线任务提供hive和spark执行引擎 5)可修改kudu存储 ➢实时平台 1)Filebeat、flume日志监控 2)Canal mysql时间数据获取 3)Kafka中间件 4)SparkStream、flink消费端 5)Kudu、hbasecunc ➢监控体系 1)zabbix硬件资源监控 2)数据质量监控 3)Yarn资源监控 4)服务是否存在监控 ➢前端展示 1)报表展示 2)Kylin OLAP 3)apache zeppelin 笔记本
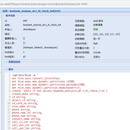
➢因为市面上常用的调度系统如azkban、ooize等等,使用都不是很方便,再加上也不满足数据治理的要求,我们调度系统是在阿里开源调度zeus的基础上,做了大量二次开发。 ➢1、使用简单:增加调度任务只要界面操作,后面会有附加的产品截图。 ➢2、权限控制:因为调度系统是开放的,大家都可使用,所以权限控制也必不可少 ➢3、资源控制:任务执行前都有判断硬件资源是不是充足 ➢4、依赖关系自动匹配:调度任务分定时任务和依赖任务,一个复杂的依赖任务,要手动配置依赖关系也是一件很痛苦的事情,但是不用怕,我们提供了自动匹配的功能 ➢5、任务多版本控制:有没有碰到过任务不小心修改错了,回不到以前的版本,我们会保留历史所有版本,随时恢复以前版本 ➢6、错误重试,任务级别设置,超时重试 ➢7、可以支持做数据治理:如数据血缘关系和数据生命周期 以上不是全部功能,因为是做二次开发,其它个性化需求都可以加上去






