

0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的叶意,一名算法工程师;
毕业于浙江万里学院,担任过杭州联保科技有限公司的算法工程师;
负责过文档查重,定损定价系统,汽车之家爬取等的开发;
熟练使用自然语言处理,数据挖掘,数据分析,爬虫
如果我能帮上您的忙,请点击‘立即预约’或‘发布需求’
APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看

1、采用scrapy框架多进程爬取车型数据 2、获取首字母从A-Z的所有车网址 3、解析品牌网址,车系网址,再到车型的详细网址 4、解析车型网页,获取在售,停售和即将销售的所有车型 5、解决车型内容html混淆,获取具体字段信息 6、获取的数据保存到Mongodb数据库
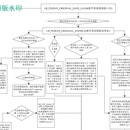
1、本项目以cx_Oracle作为存储,从数据库里提取数据集,以预测全国36个区域车型的油漆、钣金、拆装的核损工时价格 2、数据量:取1年的数据,大概1000万数据 3、以业务驱动,经过数据清洗,过滤,得到高质量数据,特征工程化后训练XGBoost模型 4、采用箱线图异常值检查方法去除异常值,特征工程中增加车系档次划分,工时项目划分 5、统计模型统计每一个区域的工时项目的核损工时价格,包括样本数,均值,中位数,众数等 6、采用机器学习框架SKlearn中的xgboost-gpu模型训练,GridSearchCV自动调参,保存最优模型 7、使用已保存的最优模型生成36个区域243个工时项目的所有数据,并保存在数据库中。 8、数据校准:模型预测价格,采用数据平滑,数据对齐,数据排序,数据填充校准价格。同时用统计模型统计出的均值,中位数,众数等参考对比校准价格。

文档查重项目 1、从数据库(Oracle数据库)里提取数据集 2、分词工具由北大pkuseg替换jieba分词,该分词工具准确率高,能分出包括英文的专有名词,能提高文档相似度效果。 3、把整篇文档内容放入模型训练,改成提取文档中的主要内容(体现文档的核心思想),过滤掉跟文档核心思想无关的噪音内容,分词后提取关键词并放入模型训练,大大提高最终效果。 4、采用聚类的方式统计所有文档的模板类型,收集所有模板的格式,按模板的格式提取文档的大段落。 5、提取大段落中的每一个中段:首先提取自然句(以句号和换行符作为判断依据),再以自然句前面的序号作为划分依据,按照数据结构切分大段落,获取中段。 6、以中段作为自然段落,源文档的自然段落和返回文档的自然段落计算相似度,获取到高于阈值(0.8)的自然段落。 7、从源文档的自然段落和返回文档的自然段落中提取含有相同的短语,用于高亮显示于前端。 8、采用多进程分布式处理所有文档(提取核心段落,分词,提取关键词等操作),速度提升90%。 9、增加日志输出,增加定时器,定时在凌晨3点更新模型并自动加载模型。 10、整个项目应用的流程:输入一个段落或整篇文档,从模型中返回N篇最相似的文档(id和相似度值),根据id从数据库中提取返回文档的内容,从返回文档的内容中提取每一个中段,与返回文档中的每一个中段两两比较,提取相似度高于阈值0.8的中段;再从中段中提取同样的短语(递归算法),高亮显示于前端。 11、在linux服务器上部署项目,安装并配置环境,后台运行接口服务。





