

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********ljava,scala,是主语言,
早期主要做微服务,高并发,
现在主要做大数据开发.
熟练掌握hadoop体系架构,深入理解HDFS、YARN以及MapReduce原理
l 精通linux,熟悉shell脚本的运维.
l 熟悉jvm架构,高并发,以及gc垃圾回收机制,以及相应的参数调优.
l 熟练使用Hive对数据进行预处理和分析,hive的15种调优。
l 熟悉sparkStreaming,sparkSQL的使用以及调优.
l 熟练掌握Hbase表结构、存储和查询。
l 熟练使用Mysql、oracle、Redis、mongodb等数据库。
l 熟练使用Java,Scala编程,了解, Python。
l 熟悉分布式应用程序协调服务 Zookeeper,统一资源管理器和调度平台 Yarn,熟悉 Sqoop 进行对数据的迁移, 利用 擅长Flume 进行数据采集,以及使用 Kafka 做消息缓冲。
l 了解Spark MLlib机器学习框架。
l 了解 CDH 平台,了解 Impala ,Oozie 的使用等。
l 了解Spark运行原理,可以使用Spark Streaming和Spark Sql组件开发实时/离线分布式计算系统,了解-Spark资源调度和任务调度源码。
l 擅长Spark性能调优,如内存调优、shuffle调优、并行度调优、数据倾斜调优等
2016-09-01 -至今京东大数据
大数据开发,flink,spark,es,sqoop, flume,kafka,hadoop,hive,hbase,mysql集群,springcloud微服务后端开发等主要工作 从事,数仓,个性化推荐,用户画像,等重要项目
2012-09-01 - 2016-06-20东北大学理论经济学本科
西方经济学,组织行为学,高等数学,统计学,模糊数学

项目以推荐系统建设领域知名的经过修改过的中文亚马逊电商数据集作为依托,以某电商网站真实业务数据架构为基础,构建了符合教学体系的一体化的电商推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
商城项目是一个综合性的 B2C 电子商务平台,功能类似于淘宝、京东。用户可以 在系统中通过搜索商品、查看商品详情、加入购物车、购买商品并生成订单完成购物操作。 商城共分为两部分:1) 商城后台管理系统: 主要实现对商品、商品分类、规格参数、CMS 等业务的处理。 2) 商城前台系统: 主要提供用户通过访问首页,完成购物流程的处理。
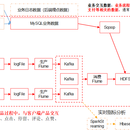
大数据的数据可视化分析,分为离线和事实, 电商项目的埋点数据入仓在pb级别的数据的数据处理,使用主流的4层模型,清洗统计图表话及其显示,日,周,月活明细表,统计新增明细表,用户留存,留存用户率,沉默用户,本周回流用户,流失用户,最近连续3周活跃用户,最近七天内连续三天活跃用户,等等数据的挖掘和清洗





