

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的【day_ue】,一名【大数据开发工程师】; 我毕业于【燕山大学】,担任过【苏宁】的【风控数据开发】,担任过【三一集团】的【孪生平台数据开发】; 负责过【通用孪生平台】,【轻量级监控】,【风险监控与预警平台】等平台的开发; 熟练使用【spark】,【flink】,【kafka】,【hadoop】,【hive】,【starrocks】,【elaticsearch】,【mysql】; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2021-11-19 -至今三一重工数据开发
负责孪生院数据架构设计和数据建模工作,撰写开发文档,以及数据接口定义;负责数仓代码管理,以及计算任务的发布部署;负责算法模型、仿真降阶模型与大数据的整合方案设计开发和部署;重点负责抓料机、旋挖钻、搅拌车等产品的孪生平台数据相关建设工作;参与需求的讨论和资源评估申请。
2018-07-15 -2021-11-01苏宁数据开发
职责:参与苏宁集团的风控需求讨论和方案设计,维护销售域数据,物流人员模型、相似地址模型、人员风险模型,离线和实时监控规则开发,工具类的开发、数据迁移任务的开发,代码工程的维护管理。 业绩:开发了物流人员模型、相似地址模型,以及人员风险模型;实时任务的开发和运维,实现监控规则动态配置化,实时告警通知,异常数据统一入库;开发维护离线任务模型3个,监控项120个;轻量级任务实例生成执行管理,任务结果去重,监控报表的自动生成,监控结果的推送,任务执行的监控,在跑任务66个。
2015-09-01 - 2018-06-01燕山大学计算机科学与技术硕士

项目描述: 建立集团产品的孪生模型,例如旋挖钻机、抓料机、挖机等,采集设备实时数据驱动产品孪生模型,通过仿真和算法模型对设备进行分析优化,实现故障预警,从而提升集团产品竞争力。 项目职责: 孪生院数据架构设计和数据建模工作,撰写开发文档,以及数据接口定义;负责数仓代码管理,以及计算任务的发布部署;负责算法模型、仿真降阶模型与大数据的整合方案设计开发和部署;重点负责抓料机、旋挖钻、搅拌车等产品的孪生平台数据相关建设工作;参与需求的讨论和资源评估申请。
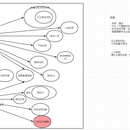
项目描述: 根据采购数据、销售数据、物流数据、资金数据、员工数据等数据源,针对风险场景,构建风险规则集,通过spark和hive任务,对风险点进行监控,并且及时消息告知业务。现有已经完成模型4个,监控项120个,每年为公司挽回上千万利润。 项目职责: 流程方案的分析讨论和设计;Hive和Spark任务,持续监控规则开发和维护;通过GraphFrame,实现物流人员模型;通过聚类、编辑距离、N-Gram、TF-IDF等算法,实现相似地址模型的开发;完成价格预警、大单预警,消息告警通知;JAVA工具类的开发,spark代码的开发,GIT工程代码的维护管理;Hive、MySQL、ES之间的数据迁移任务的开发,并且实现了代码的统一化管理。
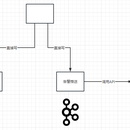
项目描述: 针对内控场景多,开发任务紧,持续性监控排期开发周期长。为了更快的响应业务方的需求,开发了轻量级监控。轻量级监控平台实现了针对业务风险数据分析人员的SQL开发页面,定时生成任务执行实例,及时推送告警消息和报表页面自动生成的功能,页面的自动去重功能,在跑任务66个。 项目职责: 流程方案的分析讨论和设计;参数的解析,通过Druid的HQL语法校验;以Spark作为底层计算引擎,任务实例调度监控,结果的存储维护;对任务实例状态的监控管理,资源消耗和异常日志的记录,保证任务的稳定运行;对业务人员提交的任务进行审核,避免资源的严重消耗和不必要的错误。





