

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********1、熟练掌握Python基础,深入理解面向对象编程思想;
2、熟练运用pandas、numpy、scipy完成数据数据预处理及基础分析;
3、熟练掌握sklearn机器学习模块,深入理解有监督学习和无监督学习;
(1) 回归分析:线性回归、岭回归、Lasso回归、多项式回归预测建模,理解梯度下降寻优;
(2) 决策树:集合算法构建随机森林模型和正向激励模型;
(3) 分类器:逻辑回归分类器、朴素贝叶斯分类器、SVM分类器,交叉验证,网格超参数寻优;
(4) 聚类算法:k-means算法、均值漂移算法、凝聚层次算法、DBSCAN算法;
4、熟悉文本分类、自动摘要、机器翻译、对话系统等常见的自然语言处理场景及相关技术;
5、能使用CNN、RNN及其变种实现各种NLP任务;
6、掌握tensorflow深度学习框架;
8、掌握Encoder-Decoder模型以及注意力机制;
2018-07-02 -至今北京公瑾科技有限公司自然语言处理
技术关键字:bert、lstm、crf、xgboost、svm、fasttext、cnn、rnn 主要任务:智能客服、命名实体识别、文本分类、知识图谱 其他:文本纠错、倒排索引、正则
2014-09-14 - 2018-06-30广东海洋大学信息与计算科学本科
数学与计算机学院 信息与计算科学 学士 优秀学生奖学金 数学建模竞赛一等奖
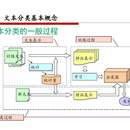
本项目属于文本分类任务,旨在对b站up主发布的客户产品引流视频的评论进行舆论监控,系统能对客户产品产生负面影响的恶意评论及时进行做出响应,由相关部门同事对恶意评论进行举报,降低影响。 项目流程 爬取b站up视频的评论数据,人工进行标注,标成3类(0-恶意,1-中性,2-好);对标注好的数据进行预处理,包括预处理后输入文本分类模型进行训练,得到文本分类模型,模型可以将用户评论分类成0-恶意、1-中性和2-好评三类,当up主的恶评数超过一定比例时会发出告警邮件,邮件和系统上都可以查看告警的详情。
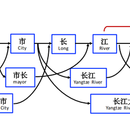
针对pdf格式的增值税发票,需要提取其中的一些关键信息进行查验,人工完成该操作费时费力,故采用自动化方式提取相关信息。 个人职责:首先对发票进行解析,得到文本后,对文本进行命名实体标注,输入到BiLSTM+CRF模型中进行训练,得到命名实体识别模型,训练后的模型可以直接对解析后的发票文本进行关键信息提取。
财税领域的智能问答系统,用户输入一句话,对这句话进行分析处理,通过文本匹配算法匹配知识库面的问题,然后返回对应的答案。 个人负责文本匹配算法的开发及服务接口的开发





