

MySQL
0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********本科大学生,开学大二,专业数字媒体技术。自学python 爬虫开发主要使用scrapy 和原生python脚本,了解selenium,bs4等html解析包。
熟悉js,html网页技术语言
数据库使用mysql,
了解php,tp5,6 。linux常用配置,nginx服务器配置
有较好的,规范的开发习惯,积极沟通,工作能力强,能独立,快速完成项目。长期接收远程工作。
目前有爬过视频网站,dandanzan10.top的视频分片ts链接,主要用断电调试破解请求参数加密。
B站视频评论爬取,其中主要是用代理来缓解ip限制。
小说,漫画等网站爬取主要是文字gbk,utf-8转码的问题。
目前正在尝试头条新闻的爬取
2018-06-05 -2022-06-03华为大数据
本科大学生,开学大二,专业数字媒体技术。自学python 爬虫开发主要使用scrapy 和原生python脚本,了解selenium,bs4等html解析包。 熟悉js,html网页技术语言 数据库使用mysql, 了解php,tp5,6 。linux常用配置,nginx服务器配置 有较好的,规范的开发习惯,积极沟通,工作能力强,能独立,快速完成项目。长期接收远程工作。 目前有爬过视频网站,dandanzan10.top的视频分片ts链接,主要用断电调试破解请求参数加密。 B站视频评论爬取,其中主要是用代理来缓解ip限制。 小说,漫画等网站爬取主要是文字gbk,utf-8转码的问题。 目前正在尝试头条新闻的爬取
2022-08-01 - 2025-07-01安徽新华学院计算机软件与理论本科
21年入学,大数据学院,学习数字媒体技术开发。平时自学python,js,php等技术
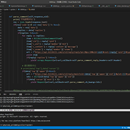
给定视频bvid,首先使用xpath解析页面,根据页数,每页数量进行评论的递归爬取并使用scrapy的管道和adbapi链接pymysql以子弹格式插入mysql数据
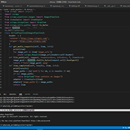
西田图片网站主要是对html解析和图片处理。html解析使用xpath,获取图片链接,然后用scrapy管道多线程下载图片原图或者缩略图,或使用scrapy进行裁剪
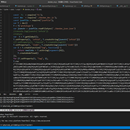
dandanzan10.top视频网站视频分片ts链接爬取,其中用scrapy框架开发,找到js加密之后使用python popen包执行nodejs脚本输出加密字符串





