

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********本人具有多年的一线互联网公司和软件开发公司工作经验,开发过多款线上产品,帮助诸多客户建立了可靠的软件产品和相关服务。尤其擅长中小型服务架构,包括前端后端以及移动端及区块链相关技术,涉及的行业包括电子商务,社交,金融等。
除软件项目的开发与管理相关的经验之外,本人还具有丰富的客户服务经验,致力于为客户提供周到的开发服务体验,于多次服务当中得到了客户的认可并且期待与诸位客户精诚协作。
技术栈编程语言: Python(熟悉),PHP (熟悉),HTML5(熟悉),JAVASCRIPT/NodeJS(一般), C/C++ (一般), Lua(一般), C#(一般)。
前端:Bootstrap(熟悉),AntD(一般),Dva(一般)。
后端: Django(熟悉), Laraval(熟悉), ThinkPHP(一般),WordPress(一般)。
爬虫:Scrapy(熟悉),自研架构(一般)。
组件:RabbitMQ(一般), Celery(熟悉), ZeroMQ(一般)。
数据库:MySQL(熟悉), Redis(一般),PostgreSQL(一般)。
运维: Ubuntu (熟悉), Nginx(熟悉),HaProxy(一般)。
架构: LAMP(熟悉), LNMP(熟悉)。
2012-10-02 -2017-08-01北京万能青年科技有限公司高级后端工程师
从事IT开发和咨询类服务的相关工作。主要使用 Django, Tornado, Laravel 以及 Redis , MySQL 等技术进行web后端开发。使用 AntD, Dva, Bootstrap 等框架进行前端相关的开发工作。
2012-05-01 -2012-09-20北京爱微创想科技有限公司高级后端工程师
担任 python/lua 程序开发实习生,app后端开发工作,和响应的appstore爬虫开发工作, 以及内部使用的ERP等。主要使用 flask 与 openresty 框架进行开发。
2009-09-01 - 2013-07-01河北大学计算机科学与技术本科
就读于此校的计算机科学与技术专业 并从事多年软件开发的相关工作
开始时间 :2018/11/05 验收时间:2018/12/06 使用技术: Python 3.6 Django 2.1.3 PIL MySQL 5.7 Celery Redis Bootstrap 该项目是一个爬虫项目,客户需求是尽量快的抓取百度百家作者的前 20 篇文章,抓取文章的同时需要为文章中的图片去除水印,并保存在本地。 该项目的开发阶段分三个,第一是文章的抓取,第二是过滤文章内容(去水印,入库),第三是文章的展示。 爬虫部分使用 celery 的定时任务,调度 requests 通过百度百家的 ajax 接口获取文章列表,然后根据列表中的 id 拼装文章详情页面的 url, 最后完成文章详情抓取。 抓取完成之后,为了抓取速度,我采用了把文章现行入库,然后等用户访问文章页面的时候再进行图片抓取和剪裁,图片的剪裁也是非常简单的,直接从底部开始去掉一部分就可以了。 爬虫的前端展示部分使用 bootstrap 进行开发。 最终爬虫的效率在客户 8C16G 的机子上跑满CPU 可以达到每小时 280 万条左右。
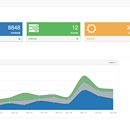
开始时间 :2016/11/03 验收时间 : 2016/11/23 使用技术: Python 3.6 Django DD Agent Opentsdb Grafana 该项目的主要业务是实现服务器性能指标数据的收集和可视化功能,客户要求参照云控来做一个类似的服务器性能指标展示和收集系统。 该系统二次开发了 ddagent,这是一个开源的 python 探针, 需要安装在客户端并实施上传数据到服务端的 opentsdb 数据库中。 展示层使用 Grafana 开发。
开始时间 :2016/06/21 验收时间 : 2016/06/28 网址: www.celuechaogu.com 使用技术: Php 5.6 Wordpress MySQL Html 5 Css 3 Javascript 这是一个官方网站开发的项目,也是我独自接活以来的第一个项目,这个项目比较简单,只是展示客户的产品,没有其他业务,客户提供了设计稿,由我来完成前端开发,后端使用 wordpress 。








