

My sql
mongo DB
爬虫与反爬虫
Scrapy、Scrapy-Redis
0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********精通Excel,world等各类办公软件,熟练掌握python常见类爬虫库以及常见数据库使用、对于爬虫日常维护管理以及设计开发驾轻就熟。在工作中具备良好的沟通协调能力,抗压能力。接受新事物能力强,同时具有很好的学习能力。注重团队合作。有过两年数字货币区块链投资与社群运营经历。¤ 热爱爬虫技术,这种不断的尝试,学习,摸索,突破到最后实现的过程,让我感到充实和满足,我相信这种热爱会让我在技术方面愈来愈完善。
性格开朗,积极主动,喜欢思考,工作中有很强的责任感。勤奋好学,为人诚恳,有良好的团队合作精神和沟通组织能力。 可以胜任重复性工作,工作细致认真、积极主动、有耐心、严谨。
2019-06-01 -2020-11-05成都利尚锦科技有限公司爬虫
责任描述: 把需要爬取的数据进行需求,分析目标网站结构以及反爬措施 通过requests,scrapy等相应手段编写爬虫技术进行内容抓取 对抓取的数据进行清洗过滤,分表存储以供公司使用 定期维护ip池,及时清除失效ip 根据所遇到的反爬手段,优化自己程序 不断学习新技术,适应各项需求并提高爬虫程序效率。
2012-09-19 - 2015-07-15西华师范大学计算机应用技术大专
在校表现优异,多次获得先进个人,多次参与校内项目制作
通过对*公众号的观察分析得知,在搜狗搜索和app及客户端比较中得 出,搜狗搜索中 并没有阅读量这一数据,故选择从电脑端api中获得文章 列表。 将MitmProxy环境部署完毕后,打开*电脑版创建一个公众号后进入公众 号页面,打开素材管理中搜索选择公众号,并随意打开一个文章,通过截 取到的json数据包中获得相应的文章标题和url地址。其中begin参数控制 翻页。 通过观察发现内容都是放在这个id=‘js_content’的div标签里的 ,获取 到url后即可遍历获取。所以需要抓取所有只需改变begin参数即可 (begin=0是第一页,begin=5是第二页,以此类推)之后打开电脑版* 公众号截取请求,发现其中大多数参数固定不变主要变量集中于3个参数, pass_ticket,appmsg_token,key,其中key参数是多次尝试后发现的时效性 最短参数,另外两个参数和不同公众号和账号本身有关 将模拟机打开并使用appnium操作*打开对应公众号第一篇取得3个变量 数值,并使用MitmProxy将3个变量通过redis导入所构建的爬虫程序中,并 设置条件当数据为空时(即参数过期)重新从MitmProxy中捕获参数导入, 爬取时通过timesleep降低爬取评率防止被封号。 在*中导入多个*账号,获取不同的appmsg_token参数,防止账号访 问频率过高被封。 在响应体参数中red_num、old_like_mum分别为阅读量、点赞量,使用json 对象数据提取方法将数据取出后使用pymysql将其保存至mysql数据库,并 存入对应字段进行保存
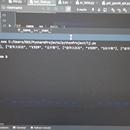
针对抖音用户页,数据页面进行抓取。抓取包括抖音用户页点赞,喜欢,作品,转载,等相关数据。 及用户点评,评论数,评论点击。通过客户userid 进行页面抓取,加密模块逆向抖音x-grogen 0404 算法获取而成。采集页面包含用户信息 并存入mysql 数据库
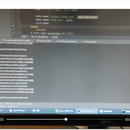
该项目分为爬虫模块数据来源站点为爱企查和企查查,通过暴力破解天眼查公司id 取得公司名称 。然后加入redis任务队列 使用gevnt从redis中取出任务异步爬取。几个服务器上搭载爬虫模块汇总统一的数据库中根据各个维度分别建表,通过MD5 值进行关联。并根据各个维度特性建造索引方便查询及去重。使用Django编写接口并写入对应sql 进行查询筛选返回数据至前端使用




