

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********1.自学能力强,容易接受并理解新知识、新事物。2.具备计算机自然语言处理和信息技术的知识素 养,具有熟练的计算机操作技能。3.为人诚实守信,团结同学,做事勤奋、严肃认真,细心,有耐 心。 4. 平时爱好读书,打羽毛球、下围棋等
2015-10-10 -2016-08-01成都清数科技研发
1. 深度学习图像识别领域相关应用:车牌识别的应用和验证码识别应用 2. Scrapy爬虫爬取科技公司相关信息和融资信息,并搭建网页服务展示
2013-09-01 - 2017-06-30电子科技大学信息与通信工程本科
在2013年入学电子科技大学,主要学习了Python/C/C++,以及深度学习的相关技术(tensorflow),实现了爬虫、网页制作的简单项目。大一学年获得了国家奖学金。大二参加了全国大学生数学建模竞赛,获得了四川省第一名。大三参加了美国大学生数学建模竞赛,获得H奖。
国际顶级期刊论文TKDE-Robust Neural Relation Extraction via Multi-Granularity Noises Reduction 论文合作者-第二作者 协助完成基于Attention神经网络关系提取器的代码

Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning 以第一作者发表了国际自然语言处理顶会EMNLP2018论文 用tensorflow实现了一个基于知识图谱的神经网络关系提取器
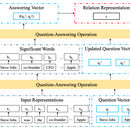
一、 信息爬取和知识图谱构建 1、使用python Scrapy爬取豆瓣读书(https://book.douban.com/tag/?view=type&icn=index-sorttags-all)下的图书基本信息,包括:类别、名称、作者、出版社、出版时间、价格、评分、评价人数、内容简介。数据量不小于5万。2、使用neo4j构建图书知识图谱。实体结点包括:图书、作者、评分、类别、出版社。图书属性:出版时间、价格、内容简介;评分属性:评价人数。 二、问答系统功能实现 1、问句理解选择基于模板匹配方式,通过朴素贝叶斯分类器对用户问句分类匹配查询模板。 2、命名实体识别采用Word2Vec字向量模型、BiLSTM-CRF模型,构建Cpyher查询语句。 三、web前端展示 1、logo图片、标题:豆瓣图书知识问答





