

MySQL掌握
0
1
2
3
4
5
本人乐观开朗,做事认真负责,上进心强,有较强的组织、管理能力,勇于承担任务与责任,能够快速接受新知识和快速适应新环境,具有良好的团队合作精神以较好的个人亲和力。良好的综合素质,具备复合型人才的条件,具有较高的交流和沟通能力,做事有条理,有较强的协调能力,争取做到在其职尽其责等
2020-11-24 -2021-02-01深圳市九学王科技有限公司数据工程师
技术信息的收集、整理,写出一些能够沿着网爬的”蜘蛛“程序,保存下来获得的信息,运用python爬取词语等信息,写入excel后分类
2018-09-01 - 2021-06-30重庆房地产职业学院互联网金融(大数据应用与分析)专科
主修课程:JavaScript,HTML前端设计,数据库,python语言,Linux操作系统,WORD、EXCEL,SPSS,电子商务数据分析与应用等
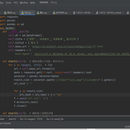
import requests import parsel import pandas as pd class Spider: def __init__(self): self.df = pd.DataFrame() self.title = ["意思", '成语接龙','成语故事','造句示例'] self.title2 = ['暂无'] self.base_url = 'https://m.autostr.org.cn/ciyu/chengyu/list-{}.html' self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} def start1(self): # 爬取词语url列表,保存为txt for i in range(1, 1372): # 页数 url = self.base_url.format(i) data = requests.get(url=url, headers=self.headers).text selector = parsel.Selector(data) result_list = selector.xpath('//*[@id="list_page"]/li/a/@href').getall() url_text = "" for j in result_list: url_text = url_text + j + "\n" f = open("url.txt", 'a') f.write(url_text) f.close()
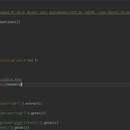
import parsel url = 'http://chenyu.00cha.com/cy/oa9sfr.html' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'} data = requests.get(url=url, headers=headers) html = data.encoding = 'gbk' html1 = data.text selector = parsel.Selector(html1) list1 = selector.xpath('//span[@class="cyh"]/text()').extract() # print(list1) # print(type(list1)) pinying1 = selector.xpath('//span[@class="cyp"]/text()').getall() # print(pinying1) detailed = selector.xpath('//div[@class="cynr"]/text()').getall() make = selector.xpath('//div[@class="cynr"]/text()[9]').extract() make1 = selector.xpath('//div[@class="cynr"]/strong/text()').extract() make2 = selector.xpath('//div[@class="cynr"]/text()[10]').extract() test = make + make1 + make2 test=''.join(test) print(test) print(type(test)) experiment = selector.xpath('//div[@class="cynr"]/text()[1]').getall() print(experiment)

import requests import parsel headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'} f = open('chengyu2_url.txt','r') lines = [line.strip('\n') for line in f.readlines()] f.close() a=0 for url in lines: a+=1 if '.asp'in url: url = 'o' print(a,url) with open('chengyu4.xlsx', 'a', encoding='utf-8')as f: f.write(url + '\n') f.close()
![]()
高级前端工程师
1000元/天
京东数科
技能:JavaScript,HTML5,CSS,Vue,React,jQuery,Angular,Ajax,跨域,axios

全栈开发
800元/天
重庆金远实业发展有限公司
技能:Vue,React,.Net,JavaScript,MySQL,SQLServer,MongoDB,TypeScript,ElementUI,Antd

前端
300元/天
重庆悦游
技能:HTML5,CSS,JavaScript,Vue,React,jQuery,ElementUI,Ajax,axios,Node.js,ES6
![]()
前端开发
400元/天
重庆前锦众程投促人力资源
技能:HTML5,CSS,JavaScript,Vue,React,ElementUI,jQuery


