

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********1.语言 : java、scala、python、shell、C、C++、SQL
2.技能 : hadoop 、spark、flink、hive、redis、hbase、kafka、flume、spring、springboot
3.擅长 : spark调优、大数据平台开发
2019-11-25 -至今深圳赢时胜信息技术股份有限公大数据开发工程师
1.负责各个业务线数据仓库建设 2.定义并开发业务核心指标数据 3.参与数据平台的搭建,优化数据处理流程具体工作 4.参与数据收集,任务调度,数据存储,查询优化等工作
2016-09-01 - 2020-06-06广州中医药大学计算机科学与技术本科
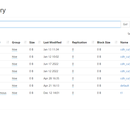
项目描述: 对数仓进行升级,将之前的部分数据处理是基于Sparksql开发的转化为HQL,对部分的数据源进行调整和数据处理的调整;不需要的业务的清除和新增业务的添加;基于之前的数据运行分析数据,提升数仓整体的运行性能。 项目职责: 1.理解原有spark代码业务,转化为HQL实现。 2.自定义的UDF和UDTF函数,对新的数据源进行处理转化,已经不需要的数据进行过滤处理。 3.已经完成交割确认的数据从交易汇总表剥离出来,建立新表,减小后期查询的数据量。 4.需要join多张大数据表的耗时流程进行优化,建立中间表或者根据业务拆表,尽量去避免后期多大表之间的join。 5.建立二级分区,一些数据处理按照ppi分区外,还可以按业务类型进行分区,对比之前的每次数据都按照全部业务类型跑数效率很大提升。 6.uat版本的HQL和生产版本的HQL区分,生产版本的不应该有注释,hive解析也需要时间(规范化) 7.后期新增的业务需要开发
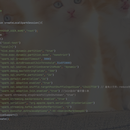
项目描述: 对上交所、深交所、北交所和沪港通每日的基金股票数据做处理。下午三点数据会发送到服务器,CD监控到数据到达,抽取数据到Linux后通过flume处理sink到hdfs,经过后续ods层到jgqr层的业务逻辑,生成数据推到下游应用端。 项目职责: 1.使用CD工具和SHELL脚本,采集Windows上面的数据到Linux中。 2.负责pre层的数据处理。在pre层为针对不同的业务逻辑对数据打上标识。 3.自定义flume的source对不同的文件数据进行解析rdb、xls等文件格式解析。 项目贡献: 1.对pre的处理逻辑做优化,需要使用到的历史数据做前置处理,过滤不需要的的数据,解决数据倾斜等问题。 2.执行交易明细层的时候,对pre表和参数表提取视图,提升交易明细层的执行效率。 3.每天业务完成后对交易明细层的小文件进行合并,提升交易汇总层的执行效率。 4.跑接口数据的时候,需要使用到最新的参数表,参数表在不断的更新,采用insert into加批次的方式解决该问题。 5.设计db2状态表和hive的业务表,理解业务,在满足业务的前提下对接口流程可能的去提升执行效率。 6.大数据集群资源有限,业务一般集中执行,需要合理为每个接口配置spark能够使用的资源,保证不同接口执行流程有足够的资源并且不会影响其它接口执行。 7.CD拉取文件数据进行改进:在windows端对批次拉取的文件打tar一次性拉取,提升效率。
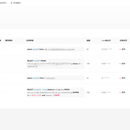
项目架构: 前端(html+css+js+vue)/vue + JavaWeb/SpringBoot + Spark/Flink + Mysql + Hive + Es + HBase + Echarts 项目描述: 平台功能项 : 任务调度功能、各领域数据指标展示面板、数据质量监测、小工具项 项目职责: 1.平台前后端搭建 2.任务调度 : 支持spark/shell/api方式,存储及展示任务执行详情(执行日志、执行时间、任务执行状态、spark任务日志分析) 3.数据展示 : 根据指标更新时间,会周期调度统计任务,并且将结果存储到mysql,展示只需从mysql拿到指标结果,通过Echarts展示 4.数据质量 : 支持通用监测及sql监测,可定时监测数据质量(字段空值率、ads/ods数据占比、敏感数据占比、正文格式定期校验排查等) 5.小工具项 : 数据删除、后端菜单节点更新、缩小hive分区等功能界面化操作




