

0
1
2
3
4
5

 ********
******** ********
********2018-06-01 -2018-09-01零点数据分析岗位
该岗位主要工作包括数据获取(爬虫等方式)、数据清洗、数据维护、数据分析等工作内容,我主要参与数据的数据获取与数据清清洗的部分
2018-09-01 - 北京大学数据科学硕士
北京大学计算机相关专业硕士在读,编程功底扎实,做事认真

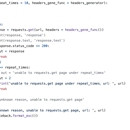
该项目的特点是,爬取网站单一但数据量要求大,甲方要求我爬取一个主题下全部历史的微博评论数据,因此和多社交媒体标准数据量爬虫不同,这个项目的主要精力放在了高效率爬虫方面,主要解决的问题有: 控制访问频率, 使用ip代理池应对反爬虫措施 解决的难点问题包括: requests模拟登录 分布式爬虫提高效率
该项目配合多重爬虫手段,爬取了微博、豆瓣、百度、天涯等主要社交媒体的数据,爬取的网站种类多,各个页面特征不一,主要解决的问题有: 分析各个平台的页面特征,制定针对化的爬虫策略 控制访问频率, 使用ip代理池 解决的难点问题包括: 模拟网站登录 分布式爬虫 模拟java script进行页面跳转

主办方给出全国数十个品牌、数百家门店的数十万条评论数据,要求参赛团队挖掘其中 的信息,该比赛系我一人独立参赛,比赛中我的工作包括: 个人职责包括: 爬虫:除主办方给出的数据外,自己爬虫餐饮店的评论数据,补充了数据来源 情感分析:使用snownlp库对每条评论数据进行情感分析,根据情感分析的评分讲评论 分为正面评论、负面评论,统计各个品牌以及不同门店的正面评论、负面评论的比例 可视化:将上述内容在地图中进行可视化,形成不同品牌、不同门店的推荐系统 链接系本人获奖的报道




