

0
1
2
3
4
5
 ********
******** ********
********2019-06-01 -至今趋研信息科技有限公司Python高级工程师
图片和文字PDF信息提取 文字PDF目前采用PDFPLUMBER,而图片PDF则自己训练相关的识别算法 EXCEL 信息提取 根据每家Excel模板提取其中的重要列 数据清洗和分析 利用Numpy,DataFrame 对常见数据进行清洗 爬虫 利用Selenium 爬虫网站表格数据, 或者一些重要的物流数据 后端开发 Django, Flask, FastAPI 后端开发 算法 主要是图片识别相关算法,对检索和排序常见算法比较熟悉,目前针对别名表采用比较先进的前缀树进行处理
2015-09-01 - 2019-06-01洛阳理工学院计算机科学与技术本科
喜欢数据结构和相关的设计模式,大三时候通过接触北京大学的Python慕课慢慢喜欢上
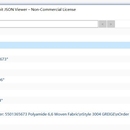
采用面向对象的设计,以及策略类的设计模式,对货运公司的各种PDF模板抽取并清洗指定数据,,以JSON形式保存,最后生成比对的EXCEL文件 亮点: 1. 采用框取关键词的四周来确定需要文本的内容 2. 公司的配置信息通过数据库来维护 3. 因为提前将数据清洗好,后面比对的过程相对简单许多 4. 采用消息队列和OSS形式来管理对货运公司的发过来的文件,方面进行模板开发和保存识别结果
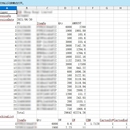
采用面向对象的设计,以及策略类的设计模式,对货运公司的各种Excel模板抽取重要列并对列数据进行清洗 亮点: 1.通过前缀树将相同含义的不同列名转化成统一列名,方面后续统一取值 2.因为各个excel的模板不同,so采用不同的策略类方面维护 3.利用FastApi实现更快的异步响应
项目描述:好酒招商网是专注于酒类批发零售的B2C电商平台, 技术支持:Python+Django+HTML5+CSS+JS+MySQL+Redis 主要职责: 1. 购物车模块的CRUD以及利用Cookie存储离线购物车数据; 2. 将第三方短信服务SDK和Celery结合,实现异步发送短信验证码; 3. 使用Redis缓存数据库中美酒信息和短信验证码; 4. 将美酒数据和Pyecharts结合,对用户选择的多个美酒进行横向对比; 5. 利用自定义分页器返回指定页的美酒数据; 6. 接入微博登录SDK; 7. 接入支付宝支付API,在蚂蚁金服沙箱环境下,测试支付模块 8. 采用Nginx反向代理和Supervisor提高并保障并发量; 9. 利用Django REST Framework实现快速开发




