

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********两年年Python爬虫开发经验,精通Python爬虫领域,熟知各类反爬手段,拥有js逆向工程,以及反制滑动验证码等反爬经验。熟练使用Asyncio异步框架进行高并发大量数据的爬虫编写。同时能够熟练使用后端框架例如Flask,Fastapi等等轻型web框架,以及前端新型框架VUE,适应于搭建各种企业环境网站。熟练的多线程,协程机制以及使用,精通Http协议、TCP/IP协议,能够使用正则表达式,Xpath,Pyquery。熟悉Redis,MySQL数据库的使用,拥有个人云服务器,能够熟练的使用Linux系统,并且能够在Linux环境下进行开发工作。
技术栈:
后端框架:Flask, Fastapi
前端框架:Vue, JavaScript
异步框架:Asyncio ,Aiohttp
数据库:Redis, MySQL
工具:Pycharm, Centos7, Git, Rabbitmq
2020-06-09 -2021-09-08小虎互联科技有限公司Python爬虫工程师
在任职期间主要负责公司的爬虫项目 1.app微博打榜模块,用户在app上登录微博后,获取cookies,在服务器上实时执行每日活动签到,转发,打榜,反黑,日活动近1W用户。 2.游戏分发渠道网站爬虫,对taptap等多个游戏app进行爬取,实现全站爬取已经增量爬取定时更新,日数据达数百万,为公司APP前期运营提供了数据支持。 3.直播网站地址解析服务,对各大直播网站的直播间地址进行解析,利用js逆向破解找到直播源地址,提供稳定接口服务。
2018-09-01 - 2023-09-01广东开放大学计算机科学与技术本科
在校期间,一直钻研Python,接触过许多开源爬虫项目,热衷于研究爬虫开发,主动报名参与了专本同读。 主修课程:计算思维、数据结构、人工智能、软件工程、SQL数据库基础 Python语言设计98分 | 专业排名 1 / 103 MySQL数据库97分 | 专业排名 1 / 1
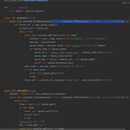
项目名称:通过异步爬虫爬取国外IMDB,烂番茄,国内豆瓣,阳光电影等知名电影网站,构建mysql数据库项目描述:对高通量测序数据进行数据分析时,需要对类型以及评分数据进行相关性筛选,为此需要构建基于评论页面详情进行爬取,抓取内容包括基因评论主体,评分,评论者,评论时间等。爬取结果存储于mysql。我的职责1,采用asyncio+aiohttp以达成高并发,异步请求。2,使用proxies国外代理,通过timeout设置超时重发机制,因为IMDB,与烂番茄是国外网站,防止因为网络卡顿导致页面抓取不到产生数据不全的现象。3,通过继承aiohttp.ClientSession类来保存cookie对象,以应对基于cookie的反扒策略4,使用xpath进行页面解析,解析出的数据通过PyMysql模块存储于mysql数据库中
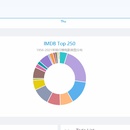
2021年8月 - 2021年9月 1.爬虫模块 ·根据需求分析使用Python编写爬虫对国内豆瓣,国外IMDB,烂番茄等有参考价值等电影网站的排行榜进行批量抓取,抓取每个电影详情页面的内容以及部分精选评论。 ·使用异步框架Asyncio,Rabbitmq重写所有网站的爬虫模块后,通过并发执行任务,提高了300%的爬取速度,大幅缩减了任务完成时间。同时改进爬虫策略,降低了被屏蔽的请求数。 2.网站项目 ·为了展示抓取的电影数据,基于Fastapi + Vue 独立构造了完整的前后端分离的web项目,使用了Echarts对电影数据进行可视化处理。 ·因MySQL的全文检索功能无法满足需求,使用Elasticsearch将已经开源的人人影视资源数据库建造了一个全文搜索引擎,现在使用者能够一键获取到电影下载链接。
设计高并发爬虫模块的主要工程师 1. 通过js逆向工程破解了NIKE登录时使用的第三方极验滑动验证码的api,为批量注册以及登录账号的效率提供了有效保障。 2.通过模拟用户点击行为,以及鼠标滑动行为,制定了爬虫策略,有效的绕过了NIKE抢购页面所使用akamai网络安全,使得抢购阶段被屏蔽拦截后的请求通过率从30%提高到90%。 3.为了方便使用,使用了vue+fastapi搭建了一个后台管理项目,能够在页面上进行批量注册,一键抢购抽签,一键下单付款等操作,目前至今已有超10万+中签记录,可在后台进行查询管理,导出操作等。



