

0
1
2
3
4
5
 ********
******** ********
********1. 熟练使用linux命令
2. 精通python,熟悉常用开源第三方库
3. 熟悉scrapy框架,可使用scrapy进行爬虫开发
4. 熟悉requests模块,可使用requests/queue/threading模块进行多线程爬虫开发
5. 熟练使用Xpath/re模块进行数据抓取
6. 熟悉Redis、MySQL、neo4j、es等主流数据库及python与数据库交互
7. 熟悉hadoop/spark大数据计算组件,熟练使用spark进行数据处理
8. 精通基于cnSchema规则的图谱创建生产
2018-08-07 -至今腾讯图谱工程师
1.负责根据需求设计网络爬虫系统,进行多平台信息的抓取和分析工作; 2.负责数据抽取、清洗、去重等工作; 3.负责根据业务场景及数据进行图谱本体构建 4.负责根据业务场景和图谱本体进行图谱生产 5.负责图谱数据入库及批量更新
2010-10-09 - 2014-08-01青岛大学物理学本科
我在青岛大学读的物理学,二专业选修计算机
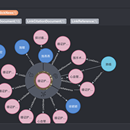
b)本体设计:本体设计主要是实体,关系,属性三元组,实体和关系会有属性,实体之间通过关系连接。 c)图谱生产:根据设计的本体,将数据生产成符合设计格式的数据并存档。 d)图谱融合:多个图谱重复相同的实体通过主键融合,融合方式包含覆盖,交集,并集,根据条件优先等多种方式 e)图谱分析:对图谱进行pagerank、社区发现、连通图等计算 f)图谱校验:对图谱数据中实体、关系、属性的覆盖率及数量进行校验,校验数据是否符合本体设计的数据格式 g)图谱发布:图谱数据发版到redis/neo4j/es
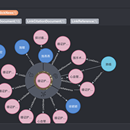
b)本体设计:本体设计主要是实体,关系,属性三元组,实体和关系会有属性,实体之间通过关系连接。 c)图谱生产:根据设计的本体,将数据生产成符合设计格式的数据并存档。 d)图谱融合:多个图谱重复相同的实体通过主键融合,融合方式包含覆盖,交集,并集,根据条件优先等多种方式 e)图谱分析:对图谱进行pagerank、社区发现、连通图等计算 f)图谱校验:对图谱数据中实体、关系、属性的覆盖率及数量进行校验,校验数据是否符合本体设计的数据格式 g)图谱发布:图谱数据发版到redis/neo4j/es
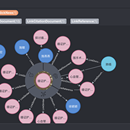
2.理财等数据直接通过python脚本入到mysql,有利于增量更新;工商涉诉数据量较大,工商涉诉数据通过spark脚本进行清洗排列,入到hive。 3.根据场景总共生产3套图谱,分别为理财问答、监管预警,风险预警。风险预警图谱包含工商、涉诉、反洗钱,贷款逾期等风险信息。图谱制作过程主要包含数据集导入,本体设计,图谱生产,图谱融合,图谱分析,图谱校验,图谱发布 a)数据集导入:数据类型主要为关系型数据库(mysql、hive等)和关系型文件(csv,excel等),也可以是单层的json结构 b)本体设计:本体设计主要是实体,关系,属性三元组,实体和关系会有属性,实体之间通过关系连接。 c)图谱生产:根据设计的本体,将数据生产成符合设计格式的数据并存档。 d)图谱融合:多个图谱重复相同的实体通过主键融合,融合方式包含覆盖,交集,并集,根据条件优先等多种方式 e)图谱分析:对图谱进行pagerank、社区发现、连通图等计算 f)图谱校验:对图谱数据中实体、关系、属性的覆盖率及数量进行校验,校验数据是否符合本体设计的数据格式 图谱发布:图谱数据发版到redis/neo4j/es




