

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********为人热情,善于沟通,热爱编程和钻研学术,有一定的爬虫技术,对于数据的挖掘和分析有浓厚的兴趣,为人真诚守信,吃苦耐劳,有较强的学习能力和逻辑分析能力。目前技术适合做一些简单的爬虫,简单的加密和逆向都可以攻破,全天在线,价格便宜,欢迎打扰。全天在线,价格便宜,欢迎打扰。全天在线,价格便宜,欢迎打扰。
APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看

1. 打开谷歌浏览器,刷新网页找到具体的请求地址 2. 网页为post请求,data里带了两个未知的参数(params,encSeckey),想办法找到这两个参数的获取方法 3. 全局代码里查询关键字 encSeckey,找到所在的代码页,找到加密的地方 4. 打上断点,反复调试,找到一些固定参数 5. 把需要的js代码搞到鬼鬼js调试工具里再反复补充所需要的代码,验证,最后成功获取到参数值 6. 在py脚本里import execjs库,来通过js代码获取我们所需要的参数值,发送post请求获取到response内容,import re库进行正则表达式获取到用户名称和用户的评论信息再import pymysql库连接到本地数据库并存再里面
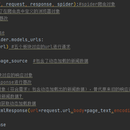
1. 手动操作一遍,看看每个板块是不是动态加载,有没有带参数 2. 在终端里 scrapy startproject wanyi 构建wanyi文档,cd进入文档,scrapy genspider wanyipy www.xxx.com 在目录下创建一个爬虫文件 3. 在items文件里建立两个对象(标题和内容) 4. 首先通过xpath爬取到首页中每个模块的href,接着对每一个板块的url进行请求发送 5. 发现每一个板块对应的新闻标题相关的内容都是动态加载,所以得导入selenium库来进行发送请求并在middlewares里拦截并篡改响应数据,再return出新的请求 6. 依次遍历通过xpath获取到每个模块下的标题和标题链接 7. 请求标题链接再通过xpath获取到对应标题下的新闻内容,import items库实例化一个item对象,赋值上标题和内容的值 再yield出去到管道类里边 8. 最后在pipelines文件里进行存储数据的操作
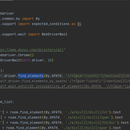
爬取斗鱼直播上面的信息,并分别提取出标题,类型,播主,在线人数。通过selenium自动化点击下一页进行分页爬取。利用xpath精准定位我们所需要的内容进行数据提取并封装输出,也可以实现在文本,excel,mysql数据库,mongodb数据库中的永久性存储。





