

负载均衡
自动化运维
监控
Zabbix
Jenkins
0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********熟练Jenkins/Jenkins pipeline+gitlab+nexus+sonarqube+maven+harbor+java这套DevOps工具链,可实现持续集成,持续部署,持续交付。
熟练Keepalived+nginx等搭建服务器群集,实现高可用和集群负载均衡
熟练zabbix/prometheus+Grafana+alertmanager等监控套件,监控软件能够对web,数据库,负载均衡、存储等服务器进行监控,并可预设报警阀值完成报警通知,达到自动化运维监控。
2017-07-01 -至今太极计算机股份有限公司Linux运维工程师
负责公司服务器的运维工作,配合研发、测试人员进行环境测试、代码上线等工作。 根据客户业务的不同进行架构设计、安装部署、以及后期的运维工作。 根据数据的重要性和生命周期的不同,制定备份、恢复、迁移和灾难备份的策略。使用shell脚本和计划任务配合,进行重要数据的备份。 编写研发、测试、线上环境统一使用的dockerfile镜像文件,docker-compose编排文件。 推进日常运维工作的自动化,提高工作效率,根据公司的未来的需求,研究运维相关技术。 编写项目部署手册,定期开展技术交流。 管理运维团队,负责日常研发、测试、线上环境工作分配,协调研发与运维人员的沟通。同时兼职测试经理职位。
2012-09-01 - 2016-06-01山西大同大学社会体育本科
顺利完成学业, 参加培训,完成技术水平提升 获得RHCE认证
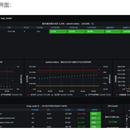
Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。现在最常见的Docker、Mesos、Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。 Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程。这样做非常适合虚拟化环境比如VM或者Docker 。
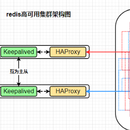
redis作为常用的缓存服务,承载着分担数据库压力的责任,单节点的redis服务,容易出现问题,采用redis-cluster的方式部署集群,尽可能的保证redis服务的稳定。
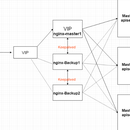
一套完整的企业级K8s集群,使用nginx+keepalived完成主备切换,实现高可用,使用etcd集群, Etcd 是一个分布式键值存储系统,Kubernetes使用Etcd进行数据存储,kubeadm搭建默认情况下只启动一个Etcd Pod,存在单点故障,生产环境强烈不建议,所以我们这里使用3台服务器组建集群,可容忍1台机器故障,当然,你也可以使用5台组建集群,可容忍2台机器故障。




