

0
1
2
3
4
5

APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
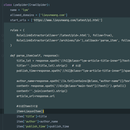
1.新建Scrapy项目 2.新建CrawlSpider爬虫 scrapy genspider -t crawl 爬虫名称 域名 3.编写规则 (爬取的URL的规则) 4.解析操作 (编写items) 5.创建数据库 (navicat for mysql )MySQL第三方图形化界面 ,创建数据表 6.编写配置文件,读取配置文件 7.数据存储 8.运行
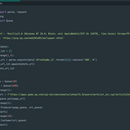
应用了生产者——消费者设计模式,批量下载王者荣耀图片,生产者生产数据放到容器中,而消费者负责消耗掉容器中的数据。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。直看代码!
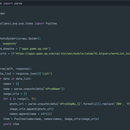
首先明确目标,要爬取什么? 我们爬取王者荣耀的图片及信息 分析页面,查看我们要获取的信息的存放位置 确定了目标,编写spider.py 编写pipelines.py,自定义图片下载设置 编写middlewares.py,在请求每个页面时,需要做反反爬操作 最后配置settings.py



