

服务器运维
自动化运维
0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********在过去的工作中,我负责监控和维护大规模的服务器和网络设备,确保系统的稳定运行。我熟练使用各种监控工具和日志分析技术,能够快速发现和解决问题,并提供及时的故障恢复措施。
我具备广泛的系统配置和部署经验,熟悉自动化工具和脚本编程,能够快速部署和更新应用程序,并确保配置的一致性和可重复性。我还有丰富的安全管理经验,能够制定和执行系统安全策略,保护系统免受潜在的安全威胁。
在故障处理方面,我善于分析和解决复杂的系统问题,与开发团队和其他相关团队密切合作,确保快速恢复服务的可用性。我注重细节和对问题的持续跟踪,以确保问题的彻底解决和防止再次发生。
我还具备容量规划和性能优化的能力,能够监测和调优系统的性能,提高系统的响应速度和效率。我热衷于学习新的技术和工具,并持续提升自己的技术能力,以应对不断变化的技术挑战和需求。
除了技术技能,我具备良好的沟通和团队合作能力。我能够与不同部门和团队进行有效的协作,共同解决问题并实现共同目标。我注重工作质量和细节,并始终保持积极的工作态度和对学习的热情。
2018-01-02 -2021-06-04北京科东电力控制运维
1、系统监控与维护:负责监控服务器、网络设备和应用程序的运行状态,及时发现并解决潜在问题,确保系统的稳定性和可用性。这包括监测系统指标、日志分析、故障排除和性能优化等。 2、系统配置与部署:负责系统环境的配置管理、软件安装与升级,以及应用程序的部署和更新。这可能涉及到使用自动化工具进行配置管理和系统部署,确保一致性和可重复性。 3、安全与备份管理:负责系统安全的管理与防护措施,包括访问控制、漏洞管理和安全审计等。此外,运维人员还需要制定和执行数据备份和恢复策略,以确保数据的安全性和完整性。 4、故障处理与紧急响应:负责故障处理和紧急响应,包括快速识别和解决系统故障,恢复服务的可用性。这可能涉及到与开发团队和其他相关团队的紧密合作,以迅速解决问题。
2009-03-01 - 2014-01-01河北工业大学计算机科学与技术本科
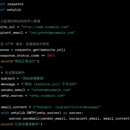
在项目中,我们建立了一套故障监测与恢复的工作流程。我们利用监控工具,如Nagios、Zabbix或Prometheus,实时监测系统的关键指标和状态。当系统出现异常情况时,我们通过配置警报规则,及时通知运维团队进行处理。 为了自动化故障恢复过程,我们采用了脚本和自动化工具。根据不同类型的故障,我们编写了相应的脚本来自动执行必要的恢复操作,如重启服务、调整配置或重新部署应用程序。我们还结合了配置管理工具,如Ansible或Puppet,来实现自动化的系统配置和环境恢复。
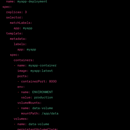
在项目中,我们使用容器编排工具,如Docker和Kubernetes,将应用程序容器化,并实现了高度可扩展的集群管理。我们设计和优化了容器镜像的构建流程,确保容器的一致性和可重复性。 通过容器编排工具,我们实现了应用程序的自动化部署和升级,减少了部署时间和人工错误。我们实现了负载均衡和自动伸缩机制,根据应用程序的负载情况动态调整集群的大小,确保高可用性和性能。 我们配置了集中式日志和监控系统,实时监控容器和应用程序的运行状态,及时发现和解决问题。我们使用容器编排工具的可视化界面,方便运维人员对集群进行管理和监控。
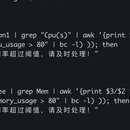
在项目中,我们首先进行了需求分析和规划,与相关团队合作确定了平台的关键功能和目标。然后,我们选择了适合的技术栈,并进行了系统架构设计和基础设施规划,确保平台的可靠性和可扩展性。 通过开发和集成各种自动化工具和脚本,我们实现了系统的监控、自动化部署、配置管理和故障排查等功能。同时,我们优化了运维流程,引入了自动化任务调度和报警机制,提高了运维团队的响应速度和效率。 在项目的优化阶段,我们通过性能分析和瓶颈识别,对平台进行了调优和优化。我们优化了数据库查询性能、优化了资源利用率,并通过引入缓存和负载均衡等策略提高了系统的可靠性和性能。




