

0
1
2
3
4
5

 ********
******** ********
********2022-08-01 -2022-08-12阿里巴巴爬虫程序员
爬取公司里的相关需要的资料,实习了一段时间,有时候需要一些外网的资料我们也会去爬取对应的字段
2009-07-07 - 2021-07-08上海中侨职业技术学院计算机应用技术专科
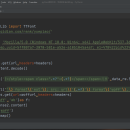
他的网站的月票数是通过特殊加密的,所以直接爬取是不行的,要先把他的加密woff文件先爬取下来保存到本地,然后把里面的映射表拿出来,一一对应上去,然后最后把我们的月票加密字体对应输出出来就能拿到数据了
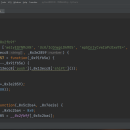
需要使用到js逆向的内容,他的数据包里面是群看不懂的英文加字母,这其实就是我们要的数据,但是得找到他的js加密文件,并把他扣下来到我们的本地运行,对这群英文数字进行解密才能拿到我们的数据。
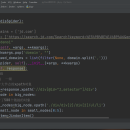
用scrapy框架爬取京东的书籍,我使用擅长的scrapy_redis的分布式爬虫,非常方便,多节点爬取,速度非常之快,然后我也有使用我的代理ip,防止被封禁ip,最后可以将几万数据很快保存下来,而且可以选择自己的保存方式





