

网络安全
爬虫
0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********会一些python基础,for循环,def调用,之类的。还会爬虫,bs4解析,和xpath解析,获取数据进行保存之类的。本人之前还学过两年运维,只不过因为某些原因没有去干相关方面工作,现在,又重新学历python 编程,希望能赚到钱。两年运维,学了点搭建lnmp,lamp,就是网页,还学过网络工程相关方面知识,比如h3c,思科,的搭建,以及docker库安装系统搭建服务等。
2021-10-21 -2022-07-13联通宽带安装宽带安装工程师
给那些顾客安装宽带,用那个光纤熔纤机熔一下什么的。我现在主要是想找个副业,就是Python ,最近都在学,做了不少案例了,比如京东上爬取数据并保存到xls文档里,在生成一个云词图。
2022-05-06 - 2022-07-08逻辑教育python初中及以下
我初中毕业后,上了一年技校,然后辍学,去某个培训机构学了两年计算机,然后去找相关工作,没找到,于是去厂里打了一年螺丝,在手机上看到逻辑教育,本来就看看,结果就报名。现在我这边是报考成考
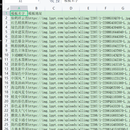
''' 目标网站:https://www.1ppt.com/moban/ 需求: 1、用多线程爬取前10页模板名字和模板详情页链接 2、把模板名字和模板详情页链接保存到模板.csv文件里面 https://www.1ppt.com/moban/ppt_moban_2.html https://www.1ppt.com/moban/ppt_moban_3.html ''' header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'} import requests import threading#导入多线程库 import csv from queue import Queue #导入队列的库 # from bs4 import BeautifulSoup from lxml import html import time print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())) etree = html.etree class One(threading.Thread): la7 = [] def __init__(self, url, data): super().__init__() self.zhen2 = url self.chao3 = data def run(self): while True: if self.zhen2.empty(): break else: zhen3 = self.zhen2.get() # print(zhen3) tm = requests.get(zhen3, headers=header) tm.encoding = 'gb2312' td = tm.text # print(td) la2 = etree.HTML(td) la3 = la2.xpath('//ul[@class="tplist"]/li') for t in la3: la6 = {} la5 = t.xpath('./a/img/@src')[0] la4 = t.xpath('./a/img/@alt')[0] la6['模板名字'] = la4 la6['模板地址'] = la5 self.la7.append(la6) with open('模板.csv', 'w', encoding='utf-8', newline='')as f: write = csv.DictWriter(f, fieldnames=['模板名字', '模板地址']) write.writeheader() write.writerows(self.la7) print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())) # la = BeautifulSoup(td, 'lxml') #转为它这个对象 # a = la.find('ul', class_="tplist") # jiem2 = a.find_all('li') # print(len(jiem2)) if __name__ == '__main__': #程序主入口 #1、创建url队列 tom = Queue() #2、创建一个放模板名字和模板的链接的队列 jemi = Queue() tom.put('https://www.1ppt.com/moban/') #生产者 for i in range(2, 11): look = f'https://www.1ppt.com/moban/ppt_moban_{i}.html' tom.put(look) # print(tom) for i in range(3): #分为三个进程 t = One(tom, jemi) t.start() #启动进程 # t.join()
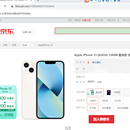
import time import re import csv import jieba import wordcloud # import faker from faker import Faker fx = Faker() from selenium import webdriver drive = webdriver.Chrome() drive.get('https://item.jd.com/100026667910.html') drive.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) drive.maximize_window() time.sleep(2) drive.find_element_by_xpath('//div[@class="ETab"]/div/ul/li[5]').click() time.sleep(2) tm = 2 li = [] com = 0 for t in range(1000): drive.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(4) drive.execute_script('window.scrollTo(0,document.body.scrollHeight)') aa = drive.find_element_by_xpath('./html') td = aa.size fd = td['height'] - 2426 drive.execute_script(f'window.scrollTo(0,{fd})') #精准打击 # drive.execute_script('window.scrollTo(0,-1420)') time.sleep(2) tm1 = drive.find_elements_by_xpath('//div[@id="comment-0"]/div')[:10] # print(len(tm1)) for i in tm1: worth = {} what = i.find_element_by_xpath('.//div[2]/p').text if len(re.findall('\n', what)) == 0: worth['京东评论'] = what else: why = what.replace('\n', '') worth['京东评论'] = why com += len(worth) print(f'已爬取{com}条数据') li.append(worth) print(f'第{t+1}页爬完') if com != 1000: if tm < 6: tm += 1 drive.find_element_by_xpath(f'//div[@class="ui-page"]/a[{tm}]').click() time.sleep(2) else: drive.find_element_by_xpath(f'//div[@class="ui-page"]/a[{tm}]').click() time.sleep(2) else: break with open('jd.csv', 'w', encoding='utf-8', newline='')as f: #将评论的数据保存到jd.csv中 write = csv.DictWriter(f, fieldnames=['京东评论']) write.writeheader() write.writerows(li) # 读取文本,就是刚刚保存的文本。然后做一个词云图 with open("jd.csv", encoding="utf-8") as f: s = f.read() # print(s) ls = jieba.lcut(s) # 生成分词列表 text = ' '.join(ls) # 连接成字符串 print(text) # stopwords = ["& hellip", "n", "&%", 'vcontent'] # 去掉不需要显示的词 wc = wordcloud.WordCloud(font_path="msyh.ttc", width=1000, height=700, background_color='white', max_words=100, stopwords=s) # msyh.ttc电脑本地字体,写可以写成绝对路径 wc.generate(text) # 加载词云文本 wc.to_file("京东好评爬取.png") # 保存词云文件
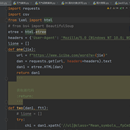
就是输入单词,利用爬虫,让他去搜索单词的词义,和单词的音标。其中利用了xpath解析,Python基础,,def函数调用,request爬虫模块,列表和字典了。





