

深度学习
机器学习
图像处理
图像识别
机器视觉
0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是思雨独辰,一名AI图像算法工程师,《机器学习入门 :基于数学原理的Python实战》作者,毕业于辽宁石油化工大学,在成都卓视智通科技有限公司担任算法总监,负责公司的算法工程的开发与优化以及整个算法工程代码重构,其中算法模型主要涉及目标检测与跟踪、行人ReID、人脸检测与识别、行人结构化属性分类、OCR。熟练使用Pytorch、TensorFlow、PaddlePaddle、TensorRT和Flask等框架。
2021-07-19 -至今成都卓视智通科技有限公司算法总监
主要参与了公司的算法⼈员招聘和算法⼯程的各个模块的性能优化和新增算法模块的模型训练、性能评估和 C++部署,涉及的算法包含:⽬标检测、⼈脸检测和识别、⾏⼈ReID、⾏⼈结构化属性分类识别、OCR、图 像上⾊、去雾和超分辨。具体⼯作包括如下: 1. 利⽤Fast-ReiD优化算法⼯程中⾏⼈ReID模块,数据集使⽤了Market1501、Cuhk03、DukeMTMCReID、MSMT17和公司实际项⽬中采集的ReID数据集和公司案例视频⾃标注困难样本ReID数据集。⼊职⼀个⽉内在Market1501、Cuhk03和DukeMTMC-ReID三⼤公开数据集上全⾯超越了竞争对⼿智慧视通2019年公开的⾏⼈ReID算法性能指标。在公司案例视频⾃标注困难样本ReID数据集上取得了90.42%的Rank1、95.29%的Rank5和96.59%的Rank10,FP16精度的TensorRT模型在RTX3090上推理速度达到10.05ms,模型体积为274.63M,并利⽤C++部署移植到公司算法⼯程中; 2. ⾃⾏利⽤Pytorch模仿Fast-ReID代码⻛格搭建图像分类框架⽤于头盔分类,包括模型
2018-08-01 - 2021-06-30中国民航大学计算机技术硕士
2014-09-01 - 2018-07-01辽宁石油化工大学计算机科学与技术本科

1.主要包括DANN模型定义、数据集定义和加载、模型训练与测试、MNIST-M数据集生成等模块; 2.使用tensorflow2.x框架和bpython进行开发,训练5000个迭代次数后MNIST-M数据集的分类准确率稳定在0.86. 3.相关详细介绍参考:https://daipuweiai.blog.csdn.net/article/details/104478550和https://daipuweiai.blog.csdn.net/article/details/104495520两篇博客

1.主要包括CGAN模型定义、数据集定义与加载、模型训练和模型测试4个模块; 2.主要使用python语言和Keras框架进行实现该项目。利用MNIS训练CGAN,经过100个epoch可以生成手写数字图像
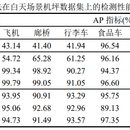
该项⽬主要是通过GAN和域⾃适应来来辅助完成机场机坪⻋辆检测,进而克服机场机坪数据严重缺少标签难 题,并适应因光照和照明灯光变换带来的场景变化。主要⼯作如下: 1. ⾸先在YOLO v3的基础上添加两个⼤尺度特征的预测分⽀,并在5个预测分⽀的上加⼊SPP模块形成 YOLO-SPP5,在训练中使⽤CIOU Loss和Focal Loss。在⽩天机坪场景数据集上达到了78.68%的 mAP。在YOLO-SPP5的基础上利⽤DarkNet-53提取得到的特征利⽤梯度反转层构建与分类器形成DAYOLO-SPP5。同时利⽤CycleGAN实现数据重建,构造⽬标域假图共享源域标签。训练过程中⽩天机坪数 据使⽤⽬标检测标签,夜晚数据则不⽤,在夜晚机坪数据集上达到了81.61%的mAP,该部分的⽹络架构 及其整体思路与ICIP2021(CCF C类会议)论⽂Multiscale Domain Adaptive YOLO for CrossDomain Object Detection基本⼀致; 2. 针对YOLO-SPP5检测速度较慢和CycleGAN图像转化质量不⾼的缺点,在YOLO-SPP5的DarkNet53特征 提取增加了SE注意⼒机制,并实现⼀定成都模型剪枝,并将多尺度特征通过渐进式上采样整合成单预测分 ⽀,形成Attention-YOLO-SPP,并与域⾃适应模块形成DA-Attention-YOLO-SPP,在训练过程中使⽤ StarGAN实现数据增强。Attention-YOLO-SPP在⽩天场景下取得了94.18%的mAP,DA-AttentionYOLO-SPP在夜晚场景下取得了80.13%的mAP






