

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********1.个人开发经历丰富,熟练使用Python,Scala开发语言,深入使用 java开发语言。
2.大数据批处理和实时处理经验丰富。
3.熟悉车企业务开发。
4.对 Spark 和 Flink 源码有深入阅读。
5.个人喜欢有挑战性的工作。
2019-07-01 -至今雁展数据开发
数据开发,1.个人开发经历丰富,熟练使用Python,Scala开发语言,深入使用 java开发语言。 2.大数据批处理和实时处理经验丰富。 3.熟悉车企业务开发。 4.对 Spark 和 Flink 源码有深入阅读。 5.个人喜欢有挑战性的工作。
2015-07-01 - 2019-07-01北京航空航天大学大数据本科
学习
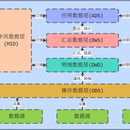
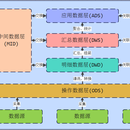
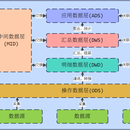
项目架构:Hadoop+spark sql+spark streaming+Mysql+Kafka+kylin+MonogDB 项目描述:主要使用SparkSQL对旗下五家子公司的数据进行数据清洗并导入到hdfs,增量数据通过spark streaming接入到hdfs,搭建数据中台数据仓库,给用户打标签,构建中台用户画像,对用户画像进行统计和聚合,做群组管理以及中台画像开启精准营销。 技术流程: 1. 使用Spark将数据采集到HDFS近源层中,用spark sql将数据清洗到ods层 2. 增量数据导入到kafka,然后spark streaming消费数据,形成小文件,合并到近源层 3. 每天对用户数据增量打标签,并形成中台画像 4. 按标签抽取用户群组,形成中台用户画像群组 5. 对部分用户群组开启精准营销活动,并统计营销活动,和用户反馈数据统计 6. 将聚合后的数据导入到kylin,kylin做预计算,后端去从kylin抽取数据 7. 对于用户基本信息、车辆信息和标签信息 则推送到MongoDB,供后端查询
将外部合作获取的全国新车销量数据、地区人口和经济数据、经销商网点和售后服务网点分布以及从各汽车网站获取的车型配置等数据整合,打造汽车行业综合信息平台。 1. 使用Python导入 每个月份销量数据、经营数据等到Mysql 2. 使用Python + Mysql 完成品牌、车系、车型的统一标准化处理 3. 使用Python + selenium 爬出国家统计局区县信息,汽车之家品牌、车系、车型和商用车等信息到Mysql 4. 使用Python + Mysql 完成销量的 全国、大区、省、市、县(区) 和品牌、车型、车型和月、季、年的环同比等各个维度计算,存入到Mysql 5. 优化Mysql查询sql,供后段查询
基于HTML5的移动跨平台引擎及集成开发环境,以及服务接入管理、移动应用管理、移动统计分析、统一消息推送,异常判断、显示。以及,各种指标的排名,前五,后五(营业部的排名)等 数据ETL Python架构设计和实现,数据库设计和SQL优化,数据处理逻辑设计,API开发,全市场交易额爬虫 Python+Oracle+Linux





