

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的pookly,
我毕业于大连理工大学,担任过海康威视的一名大数据开发工程师,最早在北京做javaWeb开发,自学转型大数据开发
参与过海康物信融合平台的开发;
熟练使用Java,Spring全家桶,SparkSQL,Linux
如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2018-10-11 -2022-12-03杭州海康威视数字技术有限公司大数据开发工程师
当前大数据技术部开发的数据处理工具种类繁多,而每类工具的实现方式又不尽相同,但是功能上基本一致,都是为了实现加载数据、处理数据、写入数据等功能,导致人员重复投入,模块重复开发,浪费了不必要的资源。本系统旨在将各类处理数据的工具实现的逻辑方式统一、抽象成不同的数据处理引擎(如处理海量数据的spark引擎、处理少量数据的dpc引擎、处理实时数据的flink引擎以及其他处理数据方式如shell脚本、python、sql等方式)、能够让各类数据处理的方式对外统一,达到部门在其他组件在选择数据处理工具时能够面对一个统一数据处理工具,从而降低数据处理工具的使用难度,并且减少维护成本和资源投入的目的。 责任描述(担任开发): 1. ⽀持丰富的IO(存储介质读写)能⼒,IO包含主流数据库如(Hbase、Kudu、Elastic Search7、Hive、Kafka2、HDFS、Postgresql、 Mysql、Oracle、Impala、Cassandra、Redis)等 2. ⽀持认证鉴权,如Kerberos认证和ranger的鉴权体系. 3. 开发少量数据处理的albatis-io及海量数据处理
2017-08-09 -2018-10-01北京掌汇天下科技有限公司Java开发工程师
为提高应用汇游戏类app下载量,要给用户`推荐用户喜欢的app,提升app广告质量 责任描述: 1、 研究适用于app广告的推荐算法 2、算法公式落地到代码,使用 Spark代码实现 3、优化Spark程序,执行时间从7min减少到3min左右,结果数据也与预期一致 4、生成app相似度结果数据并定时导出app相似度排序结果文件,压缩成tar包上传到广告系统平台
2014-07-01 - 2018-07-16大连理工大学计算机科学与技术本科

所用技术:Hive,Spark-Core,Spark-sql, Scala,Shell 开发工具:IDEA, Linux, VIM 项目说明: 为提高应用汇游戏类app下载量,要给用户`推荐用户喜欢的app,提升app广告质量 责任描述: 1、 研究适用于app广告的推荐算法 2、算法公式落地到代码,使用 Spark代码实现 3、优化Spark程序,执行时间从7min减少到3min左右,结果数据也与预期一致 4、生成app相似度结果数据并定时导出app相似度排序结果文件,压缩成tar包上传到广告系统平台 项目流程: 1、 首先建模确定数据源,把清洗过的16天用户安装app数据进行合并,取每个用户最新的行为数据并压缩成ORC作为数据源 2、 用spark-sql算出每个游戏类app的最大安装量,同时考虑对安装60个以上游戏app的用户做降权处理 3、 迭代累加所有用户产生的app相似度贡献值,同时将累加结果根据两个app拥有量进行算数平均化,对热门app做一个降权处理 4、 程序算出相似度后使用窗口函数根据app包名进行分组,相似度倒序排序,拿到每两个App相似度的排名,结果文件以orc格式保存到hdfs指定目录 5、 测试人员进行数据评测,如果app下载量提高30%以上,就证明实验成功 6、 配置Oozie定时任务,每天凌晨2点更新定时产出最新的app相似度排名文件供广告系统拉取
所用技术:Hbase、Kudu、Elastic Search6/7、Hive、Kafka2、HDFS、Postgresql、 Mysql、Oracle、Impala、Cassandra、Redis 开发工具:IDEA, Linux,Git,Maven 项目说明: 当前大数据技术部开发的数据处理工具种类繁多,而每类工具的实现方式又不尽相同,但是功能上基本一致,都是为了实现加载数据、处理数据、写入数据等功能,导致人员重复投入,模块重复开发,浪费了不必要的资源。本系统旨在将各类处理数据的工具实现的逻辑方式统一、抽象成不同的数据处理引擎(如处理海量数据的spark引擎、处理少量数据的dpc引擎、处理实时数据的flink引擎以及其他处理数据方式如shell脚本、python、sql等方式)、能够让各类数据处理的方式对外统一,达到部门在其他组件在选择数据处理工具时能够面对一个统一数据处理工具,从而降低数据处理工具的使用难度,并且减少维护成本和资源投入的目的。 责任描述(担任开发): 1. ⽀持丰富的IO(存储介质读写)能⼒,IO包含主流数据库如(Hbase、Kudu、Elastic Search7、Hive、Kafka2、HDFS、Postgresql、 Mysql、Oracle、Impala、Cassandra、Redis)等 2. ⽀持认证鉴权,如Kerberos认证和ranger的鉴权体系. 3. 开发少量数据处理的albatis-io及海量数据处理的albatis-spark-io. 4. 推⼴给其他部门同事使⽤,反馈效果符合领导预期.
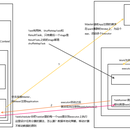
杭州市公安局现场需要多个大表去做联结查询,比如通过联结查询常住/暂住人口表、旅馆信息表、车辆卡口信息表推断出犯罪人员行动轨迹. 1. 设计统一的碰撞参数格式,支持两个或多个大表碰撞。 采用Json格式,使用二叉树数据结构来描述多表的碰撞关系.每个nodes带有碰撞字段,展示字段,字段别名.表名级URI等信息. 根节点表示碰撞中间结果. 叶子节点表示单个表. 2. 开发spring-boot碰撞服务,在碰撞接口中调用livy api,使用Apache Livy的rest api方式模拟spark submit请求 3. Spark程序接收到Json参数 ,通过递归解析二叉树的Json,读取nodes信息. 根据nodes带有的type进行碰撞计算,type>0表示该节点下有2个叶子节点,1表示并集2交集3差集. 4. 增加内源框架albatis-spark关于Elastic-Search Mongo Kudu Solr的IO支持,通过nodes中uri来判断碰撞底层的数据源,比如es与Kudu碰撞,底层就去执行SparkESInput.class与SparkKudu.class,数据传递到SparkJoinInput,最终通过SparkMongoOutput. 输出到mongo供组件组同事使用.



