

0
1
2
3
4
5

 ********
******** ********
********2021-03-01 -至今广州市钱大妈农产品有限公司价格管理人员
1.输出活动爆款数据报表,可视化展现 2.监控每日价格波动,了解价格涨幅原因 3.分析价格数据情况,了解价格波动规律 4.优化工作流程,实现数据自动化更新
2017-09-01 - 2021-06-01佛山科学技术学院食品科学与工程本科
在校成绩优异,位于年纪前30,无挂科,积极参与学校活动,热爱学习,对数学类比较感兴趣,责任心强
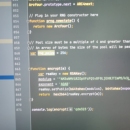
抓包分析返回的数据,在搜索查找或者链接js调用中查找相关js,把响应下来的js扣下来,然后用python进行模拟js。加密很少的js可以用python复写,但是一旦加密函数过于庞大就需要将js抽取出用python+node或是webdriver来执行相关函数。
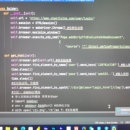
先使用Selenium对目标网页进行点击到登陆界面,然后对验证码图片的截取,可以使用第三方工具进行识别,也可以使用Python模块进行识别,但成功率不高,最后解析参数浏览器动作链点击图片
爬取首页后通过xpath匹配每个的信息块的span后构建请求,并通过scrapy.Request发送请求,用xpath匹配需要的信息。 同时循环创建下一页请求的form表单,通过scrapy.FormRequest发送POST请求。所有爬取的信息缓存到redis数据库中,最后通过编写python脚本将redis数据库中数据读取出来加入mysql数据库





