

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的范冲冲,一名python数据采集工程师; 我毕业于石家庄工程职业学院 熟练使用python数据采集,前端开发,视频剪辑 ; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2020-03-07 -2022-05-07邯郸市开发区占朝食品有限公司网页管理
在公司,担任公司网页设计,网站管理,数据采集,视频剪辑等,同时兼职网络销售管理。
2020-08-15 - 2022-06-15石家庄工程职业学院计算机应用技术专科
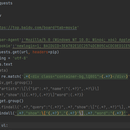
1.爬取页面源代码 import requests 2.用正则解析数据,获取整个榜单的电影名,电影类型和演员 import re 3.把数据保存到csv import csv
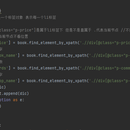
采集售卖某种的的标签,价格,评论多少,那家店,书名、 from selenium import webdriver 打开某个网址 from selenium.webdriver.common.keys import Keys 模仿鼠标 import time 时间节点 import csv 保存格式

采用模块 requests json re csv requests 获取数据 json 转换某些格式 re 获取格式中的内容 csv 来保存需要的数据 难点 json数据获取





