

0
1
2
3
4
5

 ********
******** ********
********熟悉Python语言
熟悉urllib、requests、selenium等基本爬虫的使用
熟悉爬虫多线程和多进程
熟悉常见的爬虫框架scrapy的使用和基于scrapy的分布式爬取
熟悉常见的反爬和反反爬,如验证码、滑块验证、js逆向等
熟悉基于appium的移动端爬取
熟悉数据处理和相关的各种模块,如pandas、numpy、matplotlib等
2021-03-26 -至今联想西部智能控制中心数据采集工程师
负责公司数据的采集和数据处理,通过机器学习建立模型并形成报告,制作PPT反馈给领导。
2016-09-07 - 2020-07-04成都理工大学通信工程本科
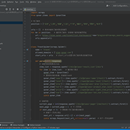
1.开发环境及三方库 Win10、pycharm、scrapy 2.基本思路 确认好目标网站后,确认需要爬取的内容,利用xpath-helper插件经行预提取。写好scrapy框架以后,再将预提取的代码放入scrapy代码中即可 3.代码编写 编辑scrapy框架,其中的难点在于页码的跳转和如何判断最后一页,需要在其中加入判断语句。
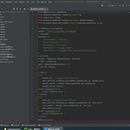
1.开发环境及三方库 Win10、pycharm、Appium、JDK、SDK、夜神模拟器、appium-python-client 2.基本思路 Appium工具可以帮助开发者定位页面数据的xpath或者id,只需要在保证Appium打开的情况下,写入初始化的设备参数即可。 3.代码编写 代码的基本编写与selenium基本一致,不同点在于移动端数据获取需要拖拽屏幕,这需要用到swipe()方法,其中的参数为start_x,star_y,end_x,end-y,所以还需要获取屏幕的宽和高,这需要用到get_window_size()[]方法。

1.开发环境及三方库 Win10、pycharm、scrapy、scrapy-redis、Xshell7、Xftp7、VMware Workstation Pro、centOS7 2.基本思路 分布式爬取需要设置一个主服务器和多个子服务器,其中主服务器的redis数据库用于存放任务url、数据和为了去重的指纹,子服务器负责从主服务器中获取任务url,并且提取数据保存到主服务中的redis数据库中。在此项目中,我使用VMware虚拟机安装了centOS7,并且安装好了项目所需要的环境和三方库,使用快照的方式克隆了两个子服务器。 3.代码编写 页码url分析、单个房源信息页码url分析。 使用Xpath-helper插件进行所需数据的提取。 需要注意的是在第三方库scrapy-redis中,有样例代码,需要将其中的settings.py文件中的代码拷贝到自己项目中的settings.py文件中来。



