

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********5年研发经验3年架构设计。
负责:1、负责公司搜索、推荐架构及开发,目前题目索引5000多万条数据,用户索引400多万,每个接口在500并发
用时两分钟的情况下平均 qps 都在300ms ,以下实现开源 canal 的高可用。
深入阅读过消息中间件的源码如 eurake、canal ,深入理解 RocketMQ、Redis、dubbo 底层架构原理,熟悉 sprin
g cloud 的各个组件 Eureka、Feign、Ribbon、Hystrix、Zuul 的工作原理。
1. 5年JAVA开发经验,深入理解JVM原理及回收机制,并对线上系统进行调优
2. 熟悉CAS、AQS、threadlocal的内部原理,深入研究过volatile的底层原理
3. 熟练使用SpringMVC、SpringBoot、dubbo 能快速搭建分布式服务
4. 深入理解分布式事物、可靠消息最终一致性方案,并在项目中有过深入实践
5. 深入了解RocketMQ消息中间件架构原理,集群部署、基于DLedger高可用原理,并在实际项目中结合可靠消息最终一致
性方案解决消息丢失、消息重复消费问题。
6. 深入理解Redis的数据备份恢复方案、高可用架构原理,对Nginx + Redis + Ehcache 多层缓存架构方案、缓存雪崩解决
方案、缓存重建并发冲突解决方案在商品详情页缓存架构中有过深入实践
7. 深入理解zookeeper分布式锁、Redis分布式锁,深入理解Curator和Redisson分布式锁框架核心源码
8. 熟悉MySQL的索引原理B-树和B+树,熟悉mysql事物可重复读的底层原理MVCC机制,能根据explain执行计划优化sql语
句
9. 熟练使用Sharding-JDBC,中间件对数据分库分表,熟悉动态扩容缩容的分库分表方案
10. 熟悉SpringCloud常用组件Eureka、Ribbon、Feign、Hystrix、Zuul架构原理
11. 熟悉分布式接口幂等性保障机制,并在实际项目有过实践
12. 深入使用elasticsearch,对索引及搜索优化有深刻的使用及设计经验
13. 深入使用并设计mysql同步数据到Elasticsearch的架构经验
14. 深入理解canal高可用,并有自己独特的高可用设计经验
2022-03-01 -2022-09-16新东方okay教育Java开发
1、负责后端搜索架构高可用设计与维护 2、 保证高峰期间接口不超时 3、 es 数据结构设计 4、 推进项目正常上线 5、 管理后端搜索组
2020-10-01 -2022-03-01一九一一未来教育科技(北京)有限公司Java开发
1、管理后端 java 部门 2、项目架构设计搭建 2、接口设计与实现 3、产品设计
2018-01-01 -2020-10-01北京新瑞理想软件股份有限公司Java开发
1、负责项目从0到1的设计、开发、上线工作 2、后端的开发工作 3、参与智能文传项目 4、林业局基本建设项目
2016-09-01 - 2019-06-01衡水职业技术学院通信技术专科
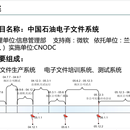
中石油智能文传项目 项目背景:为100多万中石油员工提供智能办公服务,可以快速高效的线上完成公文、督办、信息、会议等业务 项目职责:4个系统以及三个关联方的整体计划、协调工作,并独立完成一级督办系统从0到1的DDD建模设计、开发、 部署以及上线工作 工作业绩:采用RocketMQ实现一级督办、二级督办、日常催办、统推督办系统解耦、异步、一致性,极大的缩短了接 口的运行时间 项目时间:2019.1-2020.10 项目问题: 1. 督办信息发布频繁Full GC 技术挑战:高并发情况下一级督办发布督办信息后通知二级督办接收数据,由于对象太大导致新生代占满大量零 时存活对象进入老年代 ,导致JVM每隔一小时执行一次Full GC,影响系统性能 解决方案:我们机器是8核16G的,JVM参数:-Xms8g -Xmx8g -Xmn4g -XX:SurvivorRatio=6 - XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=3145728 -XX:+UseParNewGC - XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log,设计堆内 存为8G,新生代为4G,Eden和Survivor的占比为6:1:1,每个Survivor区大概占600M,保证每次young GC的时 候存活对象进入Survivor,减少Full GC 实现效果:调高Survivor区大小后,Full GC保持在每月执行一次的概率,极大提高了系统性能 2. 一级督办和二级督办强一致性分布式事务问题 技术挑战:一级督办发布督办信息后需要通知二级督办接收因为接收的二级单位是多选,在下发的时候同步下 发,一般情况下需要下发几百个二级、三级单位,每次下发在二级督办系统就要执行600ms以上的时间,如果单 位上千则时间就会达到秒级以上,极大影响了系统性能 解决方案:为了提高系统性能设计用RocketMQ异步调用二级督办,但是采用MQ会导致消息丢失、消息重复消 0mG3pcQS202210101022 费等问题,所以我采用RocketMQ的分布式事务机制发送half消息保证一级督办发送消息到RocketMQ解决消息 丢失问题,在二级督办采用Redis nx特性保证不重复消费这个消息,采用zookeeper保证数据一致性 实现效果:保证一级督办、二级督办数据最终一致性,系统间解耦,增大了系统运行效率 3. 基于 nginx + redis + ehcache 3层缓存架构的缓存雪崩问题 技术挑战:因为一级督办在每月1号并发量在五千以上,必须保证多级缓存的高可用,因为一些不可抗力尤其是 redis全体宕机,则并发全部打到数据库,直接把数据库打死 解决方案:缓存雪崩可能会导致整个系统崩溃,因此考虑了比较完善的方案,分为事前、事中、事后三个层面来 应对缓存雪崩的场景。 事前:确保Redis本身的高可用性,数据恢复备份、主从架构+哨兵,Redis cluster,一旦主节点挂了,从节 点跟上 事中:当redis不可用时,少量请求可以走缓存生产服务的本地缓存ehcache获取数据,基于hystrix对商品服 务和redis操作做限流保护 配置降级、超时、熔断策略;从而保证发生缓存雪崩时缓存生产服务不会被拖死 事后:基于redis的数据备份,快速将redis重新跑起来对外提供服务 实现效果:使用事前,事中,事后一整套方案确保了系统的的高可用性 4. 分布式缓存重建并发冲突解决方案 技术挑战:在特殊场景下数据在所有的缓存中都不存了,就需要重新查询数据写入缓存、重建缓存、分布式重建 缓存在不同的机器上,不同的服务实例中,去做上面的事情,就会导致多个机器分布式重建去读取相同的缓存, 再写入缓存,可能导致旧数据覆盖掉新数据 解决方案: 基于zookeeper分布式锁的解决方案变更缓存重建以及空缓存请求重建,更新redis之前,都需要先获取商品id的 分布式锁 拿到分布式锁之后,需要根据时间版本比较一下,如果自己的版本新于redis中的版本,那么就更新,否则就不更 新。 如果拿不到分布式锁,那么就等待,直到自己获取到分布式锁 实现效果:使同服务的不同实例强制按顺序去更新缓存,杜绝了旧数据覆盖新数据的问题 5. 获取督办信息时缓存穿透导致的MySQL压力倍增问题 技术挑战:在并发较高时,大量的请求没有命中缓存,可能导致大量流量全打在商品服务的MySQL上,导致 MySQL压力过大,有随时被打死的风险。 解决方案:使用hystrix线程池对商品服务进行限流,正常情况下,设置10个线程,并设置等待队列。 实现效果:避免了MySQL被打死的风险,确保了MySQL的可用性。 6. Nginx缓存命中率低问题 技术挑战:用户流量是均匀打落到各个nginx上去的,实际上每个nginx都会发送请求去redis上获取缓存数据, 放到自己的本地,缓存命中率很低而且导致redis的压力暴增。 解决方案:双层nginx部署架构 + lua脚本实现一致性hash流量分发策略实现效果 实现效果:Nginx缓存命中率提升了,降低了redis的压力 7. 数据库分库分表 技术挑战:随着时间的推移数据库每张表中的数据量越来越大,尤其是督办信息表,单表数据量太大导致sql执行 效率降低 解决方案:使用sharding-jdbc,将数据库水平拆分为16个库,每个库16张表,将之前的单表分成了256张表,部 署2台数据库物理服务器,数据库服务器配置为8核32G,每台物理服务器上放8个逻辑库,分库分表完成后订单 表单表数据量在120万左右。最开始采用程序对数据进行双写不停机迁移,之后如果数据量再过大直接成倍扩容 物理数据库服务器数量即可。 实现效果:将数据均匀的分到了各个库的各个表里,减少了单表数据量,提高了sql查询效率,同时实现了动态的 缩容和扩容 8. 督办信息创建等核心接口的幂等性保障 技术挑战:服务之间的重试调用,服务重复调用会导致重复创建督办信息,从而导致系统数据出现混乱。 解决方案:在开始业务逻辑处理之前,首先使用接口类名称+接口方法名称+订单唯一标识拼接这个请求对应的唯 一标识,然后基于Redis nx特性插入这个key查看是否创建督办信息的幂等性。 实现效果:通过Redis nx特性,保障了督办信息创建数据的正确性。

1911学堂-家校共育平台 涉及技术栈:springboot、springcloud、阿里云dts、Kafka、rocketmq、redis、elasticsearch、redission 项目背景:1911学堂是面向家长教育的平台,家长、教师、学校、机构、企业、政府机构入驻平台后,可以在平台发布自 己的动态、文章、直播、视频、奖学金课,也可以学习他人或机构发布的课程,可以在平台加入孩子所在的学校,创建孩子 档案,邀请亲友、老师或者学校关注,在孩子档案中可以创建孩子的校内校外学习记录、获奖记录及活动记录。 项目职责:负责公司平台的架构、设计、开发工作。 工作业绩: 架构、研发数据迁移服务采用阿里的DTS监控MySQL binlog日志,监听MySQL表结构、及数据变化后写入Kafka中, 该服务就是从Kafka中消费被修改的表结构或者数据然后写入Elasticsearch中,我在服务中采用的是配置的方式完成数 据迁移工作,只需要简单的配置即可完成具体需要迁移到ES中的表,并且可以指定具体的字段和ES索引名称。 研发平台会员、家长排行榜、孩子档案、数据统记功能。 平台性能优化工作。年前有一场各个中学在1911家校共育平台的大型直播活动,由于平台的性能问题,当每秒50的QPS 的时候服务就崩溃了 ,导致此次大型直播临时终止了。针对于这个问题对接口、前端展示做性能优化,保证每秒可以承 受上千的QPS 优化方案: 数据库:采用sharding-jdbc做读写分离,SQL上做合适的索引,优化SQL语句,避免超过两个以上连表查询,把几百 毫秒的SQL都优化到50几毫秒以内 缓存层面:对于大表SQL做mybatis二级缓存,对于文章、动态、视频、直播等的点赞、转发、收藏数量都存入redis 中,查询的时候从redis获取 搜索展示层面:用户表做迁移Elasticsearch操作,用户列表展示、全局搜索走ES查询 接口层面:做业务拆分,之前是把所有数据,包括客户端跳转之后的数据一个接口都提供了,修改后做具体的数据提 供,比如说发现页展示的是用户动态数据,里面只有动态名称及用户名称等常用字段,那么接口返回的时候就返回需要 展示的字段,其他字段客户端重新请求接口访问,保证从原来一个接口需要好几秒到现在只用不到100毫秒 通过以上数据库层面、缓存层面、分布式搜索层面保证一个接口在100毫秒以内,尤其是数据库层面避免了慢SQL、大 SQL导致MySQL负载100%

OKAY教育搜索推荐 涉及技术栈:springboot、springcloud、canal、Kafka、rabbitmq、redis、elasticsearch、nacos、 Zookeeper、redission 项目背景:围绕小初中学习、练习等研发的各端:学生机、教师空间、AI创课、APP商城、学校工作台、OMS、CMS 等。1、OKAY学习培训专用型移动智能终端,是OKAY智慧教育独立产品研发的学员专用型移动智能终端,运用于全日 制教育院校、课外辅导机构的智慧课堂情景,及学员课后练习赔偿的学生自主学习情景。2、OKAY学习培训专用型移动 智能终端,是OKAY智慧教育致力于课堂教学情景产品研发的老师专用型移动智能终端,为老师在平时课堂教学中出示* 率的信息技术应用专用工具,考虑老师常态运用的要求。3、OKAY智慧型服务平台是为地区文化教育主管机构管理人员 量身定做打造出的学生管理专用工具。 项目职责:负责elasticsearch同步mysql数据整体架构稳定、高可用、数据一致性、数据丢失补偿、节假日接口运行正 常以及各端搜索推荐功能开发等 古素福 18301545491 丨18301545491@163.com 丨北京昌平 0mG3pcQS202210101022 工作业绩:1、服务发现、注册、配置从zk迁移到nacos以及nacos配置打印到日志功能;2、canal高可用实现;3、节 假日期间学生访问量增加导致一些接口超过3秒优化,优化后接口在持续两分钟300并发的情况下都在800ms左右;4、 elasticsearch数据打平,如nested数据结构导致查询缓慢;5、ES线上6个数据节点在跑数据时数据都提交在同一个节 点上导致该节点CPU、负载都接近100%优化。 项目问题: canal服务器内存占比超过80% 技术挑战:canal服务在订阅binlog日志线上一个集群一个server对应20多个实例,每个实例都订阅一个 binlog日志在canal server中计算增删改数据并放入环形队列,在这个过程中canal server内存占比超过 80%,导致服务一直告警 解决方案: 提高canal server的内存大小、从32G换到64G的机子上,但是这样的弊端就是随着业务的增多,实例数的增 多,内存消耗也会慢慢上来,只能解决短期的问题 因为开源canal没有负载均衡,所以即使给这个集群配置多个服务,大部分实例可能还会注册到同一个服务上。 所以我采用建多个集群,每个集群对应一个服务,手动分配实例在哪个集群上,这样就可以把实例分散开来,服 务内存消耗也会降低,而且后续有新的实例可以再建集群让实例注册到新的服务。 实现效果:用第一个方案短期内也能解决问题,但是上线跑数据、节假日业务增大还是会有内存超过80%的情 况,用第二个方案让每个服务负责5个实例的订阅计算能力完全可以分散内存的消耗 es接口超时问题 技术挑战:nested做查询导致sql太长接口超时 解决方案: 可以把nested的数据打平到索引中,这样可以用terms的方式查询性能大大的提升 采用join的方式,把nested的数据放到新的子索引中,这样不仅提升性能,还能解决nested放超过3万条数据 报错,并且一次插入如果nested数据太多也会导致这条数据插入失败,造成数据不同步问题 实现效果:可以在持续两分钟300并发的情况下接口平均也能稳定在几百MS es DSL过长导致接口报错 技术挑战:线上AI创课推荐素材由于每个目录下的K都是平摊的,所以最高情况下也是中间层传500多个K请求推 荐数据,但是新业务增加游客、个人用户,这些用户都放在虚拟校不同的班级里,大数据把个人、游客可以查看 的K都放在同一个目录下导致一个目录就有2000多个K,导致一次查询一个bool条件中就有2000多个子条件,一 个bool默认只能放1024个子条件。 解决方案:基于此有两种解决办法: 修改ES配置:indices.query.bool.max_clause_count: 1024,但是如果改全局配置就要重启ES,这样风险 很大,再一个问题就是如果把这个数调大十倍,如果K的数量也增大了十倍,同样会报错 可以把一个bool拆分成多个子bool,放在同一个must中以should形式关联,这样即使有5000个子条件也不 会报错。 实现效果:保证了平台推荐运行接口不会随着条件的增多而报错 线上配置维护问题 技术挑战:每次上线的时候都是运维在配置线上配置,如果配错了线上出问题也不好排查 解决方案:基于此我把ZK的配置迁移到Nacos中,以日志的形式打印到其他的日志文件中,这样只要运维上线或 修改配置都可以在日志中看到配置的新增或变更。 实现效果:保证上线稳定性 修改索引的字段如何更好的保证机器性能 技术挑战:CMS题目管理需要增加根据创建人搜索题目,但是cms单题索引中存的搜索人名称是keyword的形 式,所以需要给该字段加上ngram、ik分词属性 解决方案:由于只更新一个字段所以不用全量跑索引,只需要根据ID变更这个一个字段即可,但是线上题目索引 5000多万条数据, 如果用update_by_query的方式服务负载和cpu会非常高 用分页的方式循环跑但是如果用from、size的方式越往后每次查的数据量会非常大,ES服务会直接挂掉 用scroll的方式滚动循环分页,ES CPU、负载基本无变化,而且5000多万条数据半个小时即可跑完 实现效果:ES服务器运行良好





