

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2022-11-07 -至今无无
暂时没有工作经验只是参加了一些校级省级国家级竞赛,例如软件杯,信创大赛,服创杯,达梦杯等
2020-10-10 - 武汉职业技术学院大数据技术与应用专科
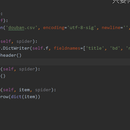
在进行豆瓣电影爬取这个项目中采用了scrapy框架进行爬取,首先在start_requests内对url进行重写再yield Requsets在parse中通过xpath对返回的网页数据进行解析和数据选择,最后在pipelines中实现持久化存储。
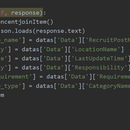
使用scrapy进行爬取,在start_requests函数内对url进行设置,使得爬取的页数可调节,还可以传入工作的类型从而实现更大范围数据的爬取,使用json.loads方法将网页数据进行爬取并且进行部分操作。使用yield返回一个Resquest接收对象为parse,再在parse中对数据进行解析和存入指向items文件中的item文件的item的对应索引下 最后在pipelines中将数据持久化存储到mysql数据库中。

项目分为url构建和middlewares的设定,spider的parse文件的编写,item文件的设置,pipelines文件写入,setting文件的设置,实现了对携程网站这类动态加载网页的全页面爬取,可以在设置了爬取页数的前提下进行自动化爬取。实现了自动翻页点击,页面保存等自动化功能。 使用re.findall方法对网页数据进行解析得到对应的目标数据,使用item接收对应数据到item中的对应的索引下,以键值对的形式存放在item这个字典中。 本程序全部由我个人完成,使用了selenium和scrapy配合使用达到爬取到携程网全数据的目的。 其中在对selenium介入scrapy的时候需要去拦截request发起的请求,需要在middlewares中对process_request方法进行重写,其中需要将selenium的方法全部写入,再导入HtmlResponse做返回值,将page_source填入到body参数,作为返回值去返回给parse中做response进行后续操作。





