

0
1
2
3
4
5

 ********
******** ********
********APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
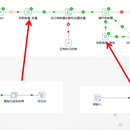
ETL是EXTRACT(抽取)、TRANSFORM(转换)、LOAD(加载)的简称。Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行, 数据抽取高效稳定。Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
功能爬取了京东商品,酷狗歌曲等内容 1)获取初始的URL。初始的URL地址可以人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。 (2)根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,先爬取当前URL地址中的网页信息,然后解析网页信息内容,将网页存储到原始数据库中,并且在当前获得的网页信息里发现新的URL地址,存放于一个URL队列里面。 (3)从URL队列中读取新的URL,从而获得新的网页信息,同时在新网页中获取新URL,并重复上述的爬取过程。 (4)满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件,爬虫则会在停止条件满足时停止爬取。如果没有设置停止条件,爬虫就会一直爬取下去,一直到无法获取新的URL地址为止。
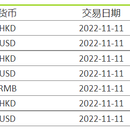
该项目本人负责从二期的需求调研,代码开发,项目演示,测试环境的发布到最后的生产投产的工作。从最早期的项目升级(jar包升级),存储过程,定时任务,二期改造其中包括后台管理系统的客户登录模块,统筹人*管理模块,客户维护管理模块,报告管理模块(定期报告,分配预案,受益凭证),邮件管理模块等等后台开发。对应的前台的报告系统,整个页面的布局,调优,报告的下载,预览以及页面各个模块之间的联系。项目于2020年3上线投产使用。





