

0
1
2
3
4
5

我是一名热衷于编程和数据科学的软件工程师,拥有扎实的Python编程技能。我对Python的灵活性、易用性和广泛的应用领域深感着迷,并一直致力于不断提升自己在这个领域的技术能力。
在过去的几年里,我参与并完成了多个Python项目,涉及领域包括网络爬虫、数据分析、机器学习、自然语言处理和网络编程等。我熟悉各种Python库和框架,如NumPy、Pandas、Scikit-learn
APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
2020-09-01 - 福建江夏学院数据科学与大数据技术本科
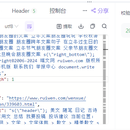
封装了4个api接口: 1. 爬取单链接: api接口:http://127.0.0.1:5000/api/v2/single/link 默认:{ url_type: single, max_depth: 0 } 用户传入 post请求 start_url 2. 根据链接下的子链接:http://127.0.0.1:5000/api/v2/single/links 默认:{ url_type: single, max_depth: 1 } 用户传入 start_url, 要想爬取更多的子链接 max_depth: 可相应修改 3. 根据链接:http://127.0.0.1:5000/api/v2/multiple/links 默认:{ url_type: multiple, max_depth: 0 } 用户输入 start_urls 列表["",""] 4. 根据链接及其子链接:http://127.0.0.1:5000/api/v2/multiple/slinks 默认:{ url_type: multiple, max_depth: 1 } 用户输入 start_urls 列表,要想爬取更多的子链接 max_depth: 可相应修改 ----------------------------------------------------------------------------------------------------- 总之一句话,爬取任意链接的文本信息(单/多,子链接),并已经封装成了api接口,你部署到云服务器上,就可以之一使用了
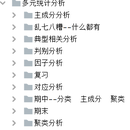
文本预处理:包括文本清洗、分词、去除停用词和标点符号等。这些步骤有助于减少噪音并将文本转化为可处理的形式。 特征提取:将文本转换为数值特征表示形式,以便应用机器学习算法。常用的特征提取方法包括词袋模型(Bag of Words)、TF-IDF(词频-逆文档频率)和词嵌入(Word Embedding)等。 主题建模,文本分类,情感分析
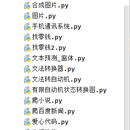
各种算法,编译原理状态转换器,二叉树,对图片的处理,自动白平衡算法,粒子群算法,bp神经网络,遗传算法,牛顿迭代,数据可视化,机器学习数据挖掘等等





