

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是一名本科大二在校学生; 我就读于深圳技术大学; 负责过自动连接校园网脚本,自动评教脚本,简易搜索引擎,github关键数据爬取脚本(5w条repo数据,每个repo有11种字段)的开发; 熟练使用selenium自动化库,numpy、pandas科学计算库,lxml、requests爬虫与网页解析库; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2021-09-01 -至今实验室数据获取
参与了一些学术工作的数据获取,如GitHub的数据获取,主要是做爬虫与数据分析方面的工作和学习,目前也在学习深度学习方面的知识
2021-09-01 - 深圳技术大学计算机科学与技术本科
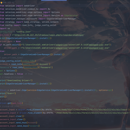
在校学生开发的脚本集合,主要是方便一些繁琐的操作 一.通过selenium自动化操作,实现自动链接校园网,具体的业务有:1.储存校园网账号密码,并且以base64编码的格式储存在本地,2.实现selenium进行网页元素的点击,实现链接校园网操作,3.实现校园网连接策略,检测当时在线的设备,低于3个在线可以直接连接,有3个设备则踢除最后一个设备,高于3个设备则是服务器端存在bug,踢除所有设备。 二.通过selenium自动化操作,实现教师自动化评测,具体的业务有:1.selenium模拟点击,实现登录获取教师课程信息,进行点击评分2.教师评分策略,用户可以直接输入[1,5]的数字一键完成该教师的20项评分。
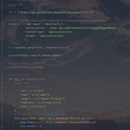
1.通过github的api进行信息获取 2.通过github的网页对于每个repo获取相应的语言、贡献者、merge次数、commit次数、fork次数、star次数,对于github的反爬措施采取一定的应对方式
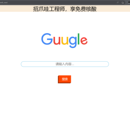
该项目用java实现了一个简易的搜索引擎,包括1.爬虫获取信息,将文档信息进行分词处理,保存2.倒排索引,利用倒排索引计算关键词相关的文档,通过词频进行相关度排序,3.rank算法,计算关键词和匹配文档的相关度,进行排序




