

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的Rudy,一名Python爬虫工程师; 爬过twitter、facebook、Instagram、tiktok、豆丁、百度知道等多个平台数据,3年以上Python爬虫开发经验,熟悉常见爬虫工作原理及针对反爬虫的应对措施,熟悉Mysql、Mongodb的操作和使用,能结合Python对大批量数据进行清洗操作; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2021-11-01 -至今中电金信Python爬虫工程师
负责公司ieg项目(腾讯IEG合作项目)爬虫系统(分布式)维护工作,包含Worker爬虫工作端(超过100个爬虫)和Server服务端(数据处理与储存-Mysql)的日常更新与维护; 根据产品侧需求开发各网站的爬虫(Python语言),并对采集内容作简单的数据处理(去重、过滤、清洗)和数据入库工作; 检测爬虫系统的爬虫任务执行情况,如果任务失败或爬虫失效则及时更新爬虫相应的适配规则以维持整个爬虫系统稳定; 定期研究网站的反爬策略(ip、cookie限制、cloudflare反爬)及相应的反反爬策略(代理、cookie频率调试、Selenium模块绕过cloudflare等),并为以后网站积累反反爬案例和经验。
2020-06-01 -2021-10-01深圳市今泰计算机技术有限公司Python爬虫工程师
寻找网站采集源(文字和ppt文档)并编写相应爬虫对内容进行采集下载和储存,对内容去重、清洗(品牌词、网址、特殊符号等)、过滤(敏感词等)处理(Python爬虫和Mongodb数据库操作); 根据不同word模板将处理后数据插入其中生成新的精品word文档; 将word、ppt文档上传到百度文库、豆丁和道客巴巴平台。
2011-09-01 - 2015-06-01广东工业大学化学工程与技术本科
构造百度搜索、搜狗搜索结果的页面链接,用request.get方法对百度搜索和搜狗搜索结果url发送请求,将response响应结果获取源码并用正则表达式提取每个搜索结果的页面排名和页面链接; 因搜狗有反爬限制,当爬虫发送请求频率太快则会被封ip,百度则正常。因此搜狗搜索发送请求时从request中添加headers请求头信息(包括ua和cookies)。再添加多个ua列表每次请求用随机ua,且每次请求时获取response返回的cookies并保存,等下次发送请求时再使用新的cookie,再降低请求频率; 从搜索结果中如果匹配到需要查询排名的域名则停止,否则一直翻页查询结果
申请相应的点点/七麦数据平台账号,通过抓包找到登录过程的请求,模拟登录请求获取登录cookie; 部分请求(登录或取榜单数据时)有部分加密参数,需通过JS逆向破解请求URL中的加密参数(点点平台的k参数、七麦平台的analysis参数); 生成账号cookie和每个请求的加密参数并挂上代理后发送请求,对响应回来的内容进行json数据解析; 将各榜单的数据保存入库并生成对应的爬虫任务进行监控。
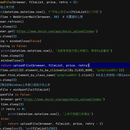
创建Chome的webdriver(浏览器)对象,打开豆丁首页并从登录框中填写豆丁账号密码进行模拟登录; 登录成功后条状到文档上传页点击上传触发文件选择窗口弹出; 用win32库中FindWindow方法定位到window弹出的文件选择框,并从文件选择框定位到文件名输入框和提交按钮,在文件名输入框填写需要上传的文档路劲并点击提交,则完成了文档上传操作; 文档上传页面中识别金额框并选择金额,在验证码输入框后将验证码图片截取(picShot方法),并用pytesseract库将图片转换成文字(英文、数字识别正确率接近100%,中文识别正确率在50%-80%之间)并将识别的文字填入验证码文本框中,提交,若验证码识别错误则刷新验证码后重复操作; 提交成功则删除刚上传的文档文件,再继续跳转到豆丁文档上传页面继续循环上传操作。




