

0
1
2
3
4
5

 ********
******** ********
********2023-02-01 -至今软帝爬虫
爬虫接单,接受了很多爬虫的单子,并且熟练使用自动化和反爬措施爬过豆瓣,拉钩,彼岸图网等等,学习了web基础运用和Java基础使用,还有c#基础和数据库基础
2022-06-01 - 湖南硅谷高科软件学院,湖北软帝Java专科
学完Python爬虫和Javaweb基础js基础
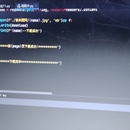
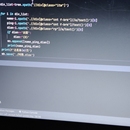
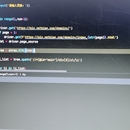
网址:http://www.cwl.gov.cn/ygkj/wqkjgg/ssq/ 爬取这个页面所有开奖数据(51页), 字段包括:期号,开奖日期,开奖*,一等奖(注数,金额),销售额,奖池金额以及对应详情页面'一等奖中奖情况





