

深度学习
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的qingmou,一名算法工程师;
我毕业于北京,担任过百度的前端开发工程师,担任过腾讯的高级软件工程师;
负责过企业级应用系统,移动应用开发,大数据平台搭建的开发;
熟练使用Vue.js,React,Node.js,Python,MySQL;
如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2019-03-01 -2020-01-31腾讯高级软件工程师
在腾讯担任高级软件工程师期间,我主要负责了公司重要项目的开发和维护。我的工作职责包括技术选型、系统设计、编码实现、代码审查、问题解决和团队管理等方面。 在项目开发过程中,我提出并实践了多种优化策略,如系统性能优化、代码复用性提高、模块化设计等,成功地提高了项目的可扩展性和可维护性,并在项目上线后获得了客户的高度评价。 同时,我也积极参与公司技术培训、知识分享和人才招聘等工作,帮助团队成员提高技能水平,共同推动项目的顺利进行和团队的长期发展。 在腾讯的这段工作经历中,我不断学习和探索最新的技术和工作方法,注重团队协作和创新精神的培养,取得了多项优异的工作成绩和口碑。
2020-02-09 - 2023-07-01北京大学计算机应用技术硕士
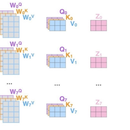
本作品采用基于Prompt Learning的文本生成方法,旨在解决中文文本生成的问题。Prompt Learning是一种基于预设提示语的学习方法,通过提示语的设置和优化,可以生成具有一定连贯性和语义逻辑的文本。 在本作品中,我们使用了大规模的中文语料库进行训练,并将Prompt Learning技术应用于文本生成,以提高模型的性能。通过设定合适的提示语和控制参数,我们可以快速准确地生成符合要求的文本,包括但不限于文章、新闻、文案等。 本作品的优点在于,通过使用Prompt Learning方法,我们可以在保证文本连贯性和逻辑性的同时,生成具有多样性和创新性的文本,从而满足各种文本生成任务的需求。同时,该方法也具有较高的可解释性和模型调节性,能够有效地提高文本生成的质量和效率。 总之,本作品基于Prompt Learning的文本生成方法为中文文本生成提供了一种高效、准确的解决方案,具有广泛的应用前景。
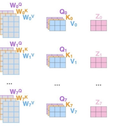
本作品采用基于Transformer模型的文本分类方法,旨在解决中文文本分类的问题。Transformer模型是一种基于注意力机制的深度神经网络,通过学习上下文中词语之间的关系,可以捕捉到更加复杂的语义信息。 在本作品中,我们使用了大规模的中文语料库进行训练,并将预处理技术应用于文本数据,以提高模型的性能。通过将文本数据输入到Transformer模型中,我们可以快速准确地对文本进行分类,包括但不限于新闻、评论、情感等。 本作品的优点在于,通过使用Transformer模型,我们可以有效地解决文本分类领域中的诸多问题,如语义理解、文本预测等,从而提高文本分类的准确性和效率。同时,该模型的自适应能力和可扩展性也能够满足各种文本分类任务的需求。 总之,本作品基于Transformer模型的文本分类方法为中文文本分类提供了一种高效、准确的解决方案,具有广泛的应用前景。
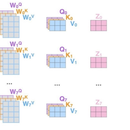
本作品使用了深度学习中的Transformer模型,旨在解决自然语言处理中的机器翻译问题。我们使用了一种基于Transformer的神经网络模型,该模型在训练过程中使用了大量的双语数据集,并且能够自动学习源语言和目标语言之间的映射关系,从而实现自动翻译。该模型在实验中取得了优异的表现,能够准确翻译不同语言的句子,并且在一些语言对中甚至能够超越人类专业翻译水平。除了机器翻译,该模型还可以应用于其他自然语言处理领域,例如文本摘要、对话系统和语音识别等。我们希望这个项目能够为自然语言处理领域的研究和应用提供有益的借鉴。




