

0
1
2
3
4
5

 ********
******** ********
********我是yan
在校大学生,学习过Python;对Python中8种数据类型的精通使用;Python匿名函数、列表推导式、装饰器的熟练使用;Python中re、requests、beautifulSoup等库的熟练使用;Python爬虫框架Scrapy的熟练使用;Python爬虫伪装中代理IP、UserAgent的熟练使用;Python与scrapyt-redis分布式爬虫的基本使用;Python操作Mysql数据库增删改查;Python操作MongoDB数据库增删改查;Python建立数据库连接池提高效率
2023-02-01 -2023-02-28无无
Python中8种数据类型的精通使用;Python匿名函数、列表推导式、装饰器的熟练使用;Python中re、requests、beautifulSoup等库的熟练使用;Python爬虫框架Scrapy的熟练使用;Python爬虫伪装中代理IP、UserAgent的熟练使用;Python与scrapyt-redis分布式爬虫的基本使用;Python操作Mysql数据库增删改查;Python操作MongoDB数据库增删改查;Python建立数据库连接池提高效率
2021-09-01 - 广西工商职业技术学院全媒体广告策划与营销专科
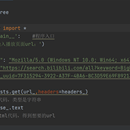
1).对'https://k.autohome.com.cn/suva1/'网址发起请求,获取响应 2).转换格式之后,用xpath解析车名与评分,获取该数据 3).xpath语法解析详情页,获取到详情页的url(url不完整),并对url进行拼接,再对详情页发起请求 响应数据 4).通过xpath获取到特点,获取到的特点数据中带有空格符号,需进行删除操作; 5).因价格也在详情页当中,可以直接利用xpath语法获取到价格的数据 6).数据获取完成;就要把数据写入到表格当中,先创建对象,再把数据写入表格
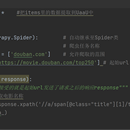
首先爬取首页后通过xpath匹配每个的信息块的span后构建请求,并通过scrapy.Request发送请求,用xpath匹配需要的信息。 同时循环创建下一页请求的form表单,通过scrapy.FormRequest发送POST请求。所有爬取的信息缓存到redis数据库中, 最后通过编写python脚本将redis数据库中数据读取出来加入mysql数据库。






