

SQL Server
0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********2022-09-01 -至今埃森哲数据分析师
1.负责日常业务问题的监控,及时预警系统风险并给出解决方案 2.协助数据开发人员进行平台开发,提供数据模型测试案例 3.参与数据模型优劣分析,完成模型准确率分析报告 4.积极同其他模块展开沟通,确保各模块不出现认知偏差
2018-09-01 - 2022-06-01上海第二工业大学智能科学与技术本科
相关课程:数据结构与算法,智能统计学,人工智能基础。 英语6级516 四级579 计算机二级 90 大学平均绩点 3.53

项目需要利用已有的与目标客群稍有差异的个人信贷数据,辅助目标风控模型的创建,并利用该风控模型实现新业务下的用户违约预测。 模型选择为lightgbm + lr 处理过程分为以下几个步骤: 特征选择 选取符合条件的特征,根据相关性、缺失率、IV等指标 数据划分 按照一定比例划分训练集和验证集,用于模型训练和验证 数据转化 利用lightgbm模型把源数据输出为叶子节点矩阵并把此作为lr模型新的输入。 卡方分箱 利用分箱把连续值离散化,手动调整分箱单调性让分箱结果更贴合真实业务场景 WOE编码 为各个分箱分配不同权重,并通过设置IV阈值处理过拟合,得到新数据集 模型训练 输入新数据集并设置模型参数来解决样本不平衡现象,通过训练得到模型 模型验证 绘制ROC,根据AUC值评估模型灵敏度,根据k-值评估模型区分好坏客户的能力 技术栈:Python + Pandas + Numpy + Sklearn + LR + Matplotlib

项目需要利用已有的与目标客群稍有差异的个人信贷数据,辅助目标风控模型的创建,并利用该风控模型实现新业务下的用户违约预测。 模型选取lightgbm模型 处理过程分为以下几个步骤: 特征选择 选取符合条件的特征,根据相关性、缺失率、IV等指标 数据划分 按照一定比例划分训练集和验证集,用于模型训练和验证 模型训练 输入新数据集并设置模型参数来解决样本不平衡现象,通过训练得到模型 模型验证 绘制ROC,根据AUC值评估模型灵敏度,根据k-值评估模型区分好坏客户的能力 技术栈:Python + Pandas + Numpy + Sklearn + LR + Matplotlib
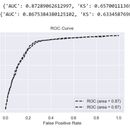
项目需要利用已有的与目标客群稍有差异的个人信贷数据,辅助目标风控模型的创建,并利用该风控模型实现新业务下的用户违约预测。 由于借贷数据特征以连续型为主,故本人选取解释性更好,更适合连续型数据的逻辑回归模型。 处理过程分为以下几个步骤: 特征选择 选取符合条件的特征,根据相关性、缺失率、IV等指标 数据划分 按照一定比例划分训练集和验证集,用于模型训练和验证 卡方分箱 利用分箱把连续值离散化,手动调整分箱单调性让分箱结果更贴合真实业务场景 WOE编码 为各个分箱分配不同权重,并通过设置IV阈值处理过拟合,得到新数据集 模型训练 输入新数据集并设置模型参数来解决样本不平衡现象,通过训练得到模型 模型验证 绘制ROC,根据AUC值评估模型灵敏度,根据k-值评估模型区分好坏客户的能力 技术栈:Python + Pandas + Numpy + Sklearn + LR + Matplotlib





